Title: How to Connect Speech Foundation Models and Large Language Models? What Matters and What Does Not
Authors: Francesco Verdini, Pierfrancesco Melucci, Stefano Perna, Francesco Cariaggi, Marco Gaido, Sara Papi, Szymon Mazurek, Marek Kasztelnik, Luisa Bentivogli, Sébastien Bratières, Paolo Merialdo, Simone Scardapane
Published: 25th September 2024 (Wednesday) @ 15:54:29
Link: http://arxiv.org/abs/2409.17044v1
Abstract
The remarkable performance achieved by Large Language Models (LLM) has driven research efforts to leverage them for a wide range of tasks and input modalities. In speech-to-text (S2T) tasks, the emerging solution consists of projecting the output of the encoder of a Speech Foundational Model (SFM) into the LLM embedding space through an adapter module. However, no work has yet investigated how much the downstream-task performance depends on each component (SFM, adapter, LLM) nor whether the best design of the adapter depends on the chosen SFM and LLM. To fill this gap, we evaluate the combination of 5 adapter modules, 2 LLMs (Mistral and Llama), and 2 SFMs (Whisper and SeamlessM4T) on two widespread S2T tasks, namely Automatic Speech Recognition and Speech Translation. Our results demonstrate that the SFM plays a pivotal role in downstream performance, while the adapter choice has moderate impact and depends on the SFM and LLM.
This pre-print/paper came from theMeetween consortium, in particular Translated and FBK. ACC Cyfronet AGH supplied compute infra.
Rejected from ICASSP 2025 (submission in Sept. and decision in December ‘24).
Why was this rejected? (Substance of the work seems reasonable to me.) Conclusions on the main question comparing LLMs x length adapters is muddled but the empirical results are the results. Criticism of not having apple-for-apples baseline isn’t fair I don’t think? They compare against Qwen-Audio which also initialises its audio encoder with Whisper
Overview
Try combinations of:
- SFM: Whisper large-v3 and SeamlessM4T v2-large - they keep SFMs frozen ❄️
- “usage of SeamlessM4T has never been explored to the best of our knowledge”
- both process audio sequences where each vector of the sequence represents 10ms of audio, Whisper emits one vector every 20ms (2× downsampling), while SeamlessM4T encoder returns one vector every 160ms (16× downsampling)
- SeamlessM4T is built with a customized version of Conformer layers
- Length Adapters (modality always Transformer encoder stack)
- they only investigate length and not modality adapters, opting for a vanilla Translated encoder stack as the modality adapter:
- “As we keep the SFM and LLM frozen, we design adapters with high representation capacity, allowing for an effective mapping of the embeddings to the LLM input space”
- adapters are trained using a cross-entropy loss on the output of the LLM having the transcripts for ASR and translations for ST as target
- LLMs (goal is to “maximise the difference between the investigated LLMs”)
- Mistral-7B-Instruct-v0.3 - English-centric
- Llama-3.1-8B-Instruct - trained in a multilingual setting, covering English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai
Length Adapters Experimentally Evaluated
- Base. 4 Transformer encoder layers are used and no length adaptation is performed.
- Conv-based. 2 convolutional layers with stride 2 are introduced after the second layer of the Base adapter. No auxiliary loss is used. The final compression factor is 4.
- CIF-based. Similarly to Conv-based, the adapter is extended by introducing a Continuous Integrate-and-Fire (CIF) length adapter after the second Transformer layer.
- CIF is a sequence compression mechanism that accumulates input features over time and emits an output when a given integration threshold is reached, enabling variable-length sequence compression while preserving key information. To train this module, we add two auxiliary losses: a Connectionist Temporal Classification (CTC) loss 21 with the transcripts as target, following 22, and a quantity loss that controls the compression factor. The weight associated to both auxiliary losses is 0.1. On average, this corresponds to a compression factor of 2 with SeamlessM4T and 12 with Whisper.
- CTC-based.
- use CTC-based Compression for Direct Speech Translation from Marco Gaido and co inc. Mauro Cettolo, Matteo Negri and Marco Turchi from FBK
- In this case, the length adapter is a CTC-based compression 11, which collapses consecutive equal predictions of a CTC module by averaging the corresponding vectors, trained on the transcripts with an auxiliary CTC loss as done in CIF-based. On average, this corresponds to a compression factor of 1.5 for SeamlessM4T and 9 for Whisper.
- WLQ-former - Window-level Q-former
- the windowed version of Q-former from SALMONN; note/recall the Q-former is from the BLIP-2 paper
- This adapter performs both modality and length adaptation with a window-level Q-Former 3. This module processes variable-length encoded speech sequences by dividing them into fixed-length windows of encoded frames and feeding each of these non-overlapping windows to a Q-former architecture 23. The Q-former uses a fixed and configurable number of learnable query vectors to attend to each window through cross-attention. As a result, the compression factor is controlled by the window length and the number of queries, which we set to 0.33 seconds and 1 respectively as per 3, and therefore results in 2 for SeamlessM4T and 16 for Whisper.
TABLE I: Compression rate for each configuration of SFM/Adapter.
| SFM | Adapter | Compression ratio Sampling rate (Hz) | |
|---|---|---|---|
| Base | 1:1 | 6.25 | |
| CIF-based | 3:1 | 2.08 | |
| Seamless | Conv-based | 4:1 | 1.56 |
| CTC-based | 2:1 | 3.12 | |
| WLQ-former | 2:1 | 3.12 | |
| Base | 1:1 | 50.00 | |
| CIF-based | 25:1 | 2.00 | |
| Whisper | Conv-based | 4:1 | 12.50 |
| CTC-based | 13:1 | 3.85 | |
| WLQ-former | 16:1 | 3.12 |
TABLE II: Number of parameters for each adapter
| Adapter | # trainable parameters (M) | ||
|---|---|---|---|
| len. adapt. | mod. adapt. | Total | |
| Base | 0 | 28.35 | 28.35 |
| Conv-based | 25.20 | 28.35 | 53.55 |
| CIF-based | 28.15 | 28.35 | 56.50 |
| CTC-based | 25.20 | 28.35 | 53.55 |
| WLQ-former | 33.09 | 33.09 |
Experimental Settings
Data
Trained all models on
- CoVoST 2 with
- source languages: English, German, Spanish, French, and Italian
- target languages: German and English
- MuST-C a Multilingual Speech Translation Corpus
- target languages: German, French, Italian, Spanish
Datasets for ASR obtained by:
- CoVoST 2: take audios in source languages and their transcriptions
- MuST-C we took audios and associated transcriptions from the English-German partition
Hyperparameters / Training setup
- 2 epochs 28k steps
- 4 NVIDIA GH200 96GB GPUs
- micro-batch size of 10 samples with 4 gradient accumulation steps batch size of 160 samples
- took last checkpoint as the final model
Results
- our Whisper, Base adapter, and Llama model – a basic configuration adopted by previous SFM+LLM works – scores 28.7 BLEU on CoVoST en-de (the most popular language direction), a significantly higher result than the 25.1 BLEU of Qwen-Audio, one of the best performing SFM+LLM solutions
- the SFM is the most critical factor - SeamlessM4T outperforms the counterpart with Whisper on both tasks (ASR and ST) on average
- choice of LLM less critical
- small gap (<0.2 on both ASR and ST) between best Llama (Seamless as SFM and WLQ-former as adapter) and Mistral (SeamlessM4T as SFM and Base as adapter
- there is no one-size-fits-all solution for the length adapter
- I guess this is inconsistent and hard to interpret/take home learnings from
TABLE III: ASR and ST results on CoVoST test sets.
The best result for each (SFM, LLM) configuration is underlined, while the overall best is bolded. The difference with Base is statistically significant (p<0.05) unless for scores marked with ∗. 👈 weird thing they did; usually it’s the opposite
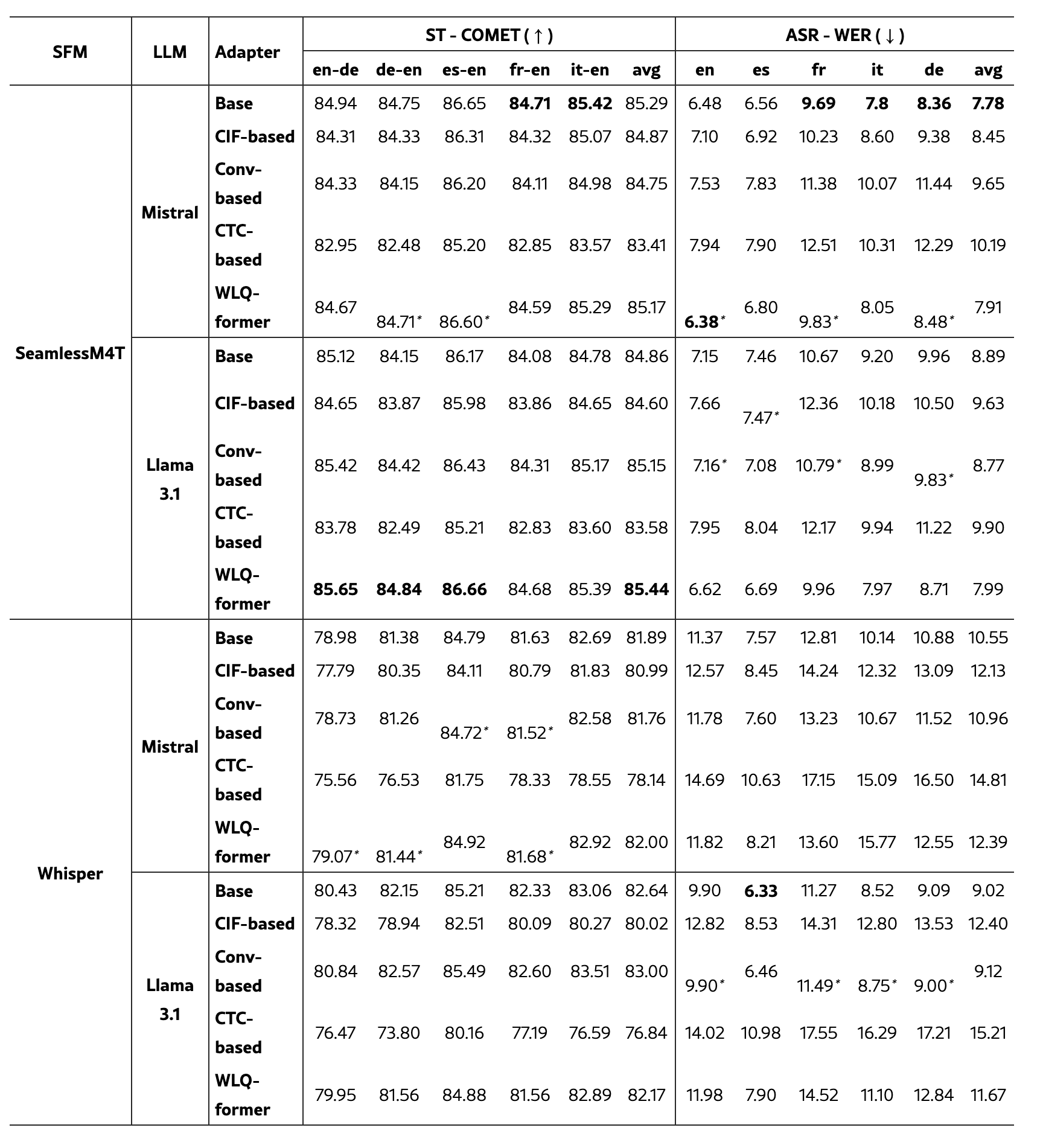
Figure 1: Schema of SFM + LLM Architecture
