Codec SUPERB
Excerpt
Codec Speech processing Universal PERformance Benchmark Challenge
Codec SUPERB Challenge @ SLT 2024
Codec Speech processing Universal PERformance Benchmark Challenge
Introduction
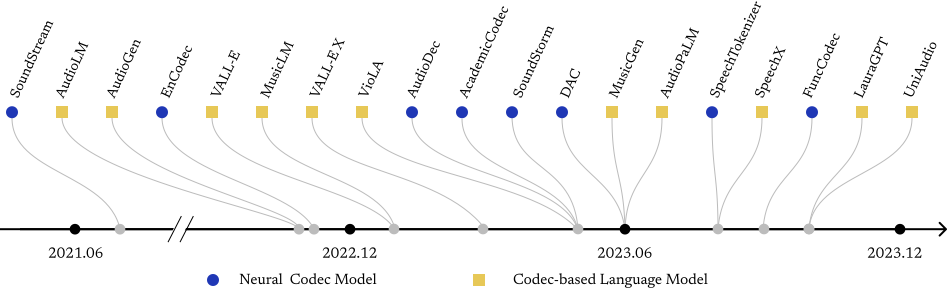
Neural audio codecs are initially introduced to compress audio data into compact codes to reduce transmission latency. Researchers recently discovered the potential of codecs as suitable tokenizers for converting continuous audio into discrete codes, which can be employed to develop audio language models (LMs). The neural audio codec’s dual roles in minimizing data transmission latency and serving as tokenizers underscore its critical importance. The ideal neural audio codec models should preserve content, paralinguistics, speakers, and audio information. However, the question of which codec achieves optimal audio information preservation remains unanswered, as in different papers, models are evaluated on their selected experimental settings. There’s a lack of a challenge to enable a fair comparison of all current existing codec models and stimulate the development of more advanced codecs. To fill this blank, we propose the Codec-SUPERB challenge.
The goal of this challenge is to encourage innovative methods and a comprehensive understanding of the capability of codec models. This challenge will conduct a comprehensive analysis to provide insights into codec models from both application and signal perspectives, diverging from previous codec papers that predominantly focus on signal-level comparisons following the paper Codec-SUPERB: An In-Depth Analysis of Sound Codec Models (Wu et al., arXiv 2024). The diverse set of signal-level metrics, including Perceptual Evaluation of Speech Quality (PESQ), Short-Time Objective Intelligibility (STOI), Mel distance, and Signal-to-Distortion Ratio (SDR) enable us to conduct a thorough evaluation of sound quality across various dimensions, encompassing spectral fidelity, temporal dynamics, perceptual clarity, and intelligibility. The application angle evaluation will comprehensively analyze each codec’s ability to preserve crucial audio information, encompassing content, speaker timbre, emotion, and general audio characteristics. We hope this challenge can inspire innovative research in neural codec development. With this proposal, we aim to promote innovation in neural audio codec fields and advancing the research frontier.
Timeline / Important Dates
- Data available for public-set (Hidden-set will be hidden throughout the challenge)
Rule announcement: 2024-04-29[Rule with Baselines]Submission start: 2024-04-29- Submission deadline: 2024-06-20
- Results announcement and hosting challenge: 2024-12
Organizers
Academia
- Hung-yi Lee (NTU) website
- Haibin Wu (NTU) website
- Kai-Wei Chang (NTU) website
- Alexander H. Liu (MIT) website
- Dongchao Yang (CUHK) website
- Shinji Watanabe (CMU) website
- James Glass (MIT) website
Industrial
Technical Committee
- Ho-Lam Chung (NTU)
- Yi-Cheng Lin (NTU)
- Yuan-Kuei Wu (NTU)
- Xuanjun Chen (NTU)
- Ke-Han Lu (NTU)
- Jiawei Du (NTU)
References
[1] Wu, Haibin, et al. “Towards audio language modeling-an overview.” arXiv preprint arXiv:2402.13236 (2024).
[2] Wu, Haibin, et al. “Codec-SUPERB: An In-Depth Analysis of Sound Codec Models.” arXiv preprint arXiv:2402.13071 (2024).
[3] Neil Zeghidour et al., “Soundstream: An end-to-end neural audio codec,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021.
[4] Zalan Borsos et al., “Audiolm: a language modeling approach to audio generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
[5] Felix Kreuk et al., “Audiogen: Textually guided audio generation,” arXiv preprint arXiv:2209.15352, 2022.
[6] Défossez, Alexandre, et al. “High fidelity neural audio compression.” arXiv preprint arXiv:2210.13438 (2022).
[7] Chengyi Wang et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
[8] Andrea Agostinelli et al., “Musiclm: Generating music from text,” arXiv preprint arXiv:2301.11325, 2023.
[9] Ziqiang Zhang et al., “Speak foreign languages with your own voice: Cross-lingual neural codec language modeling,” arXiv preprint arXiv:2303.03926, 2023.
[10] Jenrungrot, Teerapat, et al. “LMCodec: A Low Bitrate Speech Codec with Causal Transformer Models.” ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.
[11] Tianrui Wang et al., “Viola: Unified codec language models for speech recognition, synthesis, and translation,” arXiv preprint arXiv:2305.16107, 2023.
[12] Jiang, Xue, et al. “Latent-Domain Predictive Neural Speech Coding.” IEEE/ACM Transactions on Audio, Speech, and Language Processing (2023).
[13] Yi-Chiao Wu et al., “Audiodec: An open-source streaming high- fidelity neural audio codec,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
[14] Dongchao Yang et al., “Hifi-codec: Group-residual vector quantization for high fidelity audio codec,” arXiv preprint arXiv:2305.02765, 2023.
[15] Borsos, Zalán, et al. “SoundStorm: Efficient Parallel Audio Generation.” arXiv preprint arXiv:2305.09636 (2023).
[16] Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar, “High-fidelity audio compression with improved rvqgan,” arXiv preprint arXiv:2306.06546, 2023.
[17] Jade Copet et al., “Simple and controllable music generation,” arXiv preprint arXiv:2306.05284, 2023.
[18] Paul K Rubenstein et al., “Audiopalm: A large language model that can speak and listen,” arXiv preprint arXiv:2306.12925, 2023.
[19] Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu, “Speechtokenizer: Unified speech tokenizer for speech large language models,” arXiv preprint arXiv:2308.16692, 2023.
[20] Xiaofei Wang et al., “Speechx: Neural codec language model as a versatile speech transformer,” arXiv preprint arXiv:2308.06873, 2023.
[21] Ratnarajah, Anton, et al. “M3-AUDIODEC: Multi-channel multi-speaker multi-spatial audio codec.” arXiv preprint arXiv:2309.07416 (2023).
[22] Xu, Zhongweiyang, et al. “SpatialCodec: Neural Spatial Speech Coding.” arXiv preprint arXiv:2309.07432 (2023).
[23] Zhihao Du, Shiliang Zhang, Kai Hu, and Siqi Zheng, “Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec,” arXiv preprint arXiv:2309.07405, 2023.
[24] Qian Chen et al., “Lauragpt: Listen, attend, understand, and regenerate audio with gpt,” arXiv preprint arXiv:2310.04673, 2023.
[25] Dongchao Yang et al., “Uniaudio: An audio foundation model toward universal audio generation,” arXiv preprint arXiv:2310.00704, 2023.
[26] Ji, Shengpeng, et al. “Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models.” arXiv preprint arXiv:2402.12208 (2024).
[27] Liu, Haohe, et al. “SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound.” arXiv preprint arXiv:2405.00233 (2024).
[28] Ai, Yang, et al. “APCodec: A Neural Audio Codec with Parallel Amplitude and Phase Spectrum Encoding and Decoding.” arXiv preprint arXiv:2402.10533 (2024).