Zero-Shot Tokenizer Transfer for transferring LLMs to a new tokenizer without any training | by SACHIN KUMAR | Medium
Excerpt
Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts their flexibility: for example, LMs trained primarily on English may…
[

Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts their flexibility: for example, LMs trained primarily on English may still perform well in other natural and programming languages, but with decreased efficiency.
To mitigate it, this paper [1] proposes Zero-Shot Tokenizer Transfer (ZeTT).
Key contributions:
- propose a new solution of training a hypernetwork taking a tokenizer as input and predicting the corresponding embeddings.
- empirically demonstrate that the hypernetwork generalizes to new tokenizers both with encoder (e.g., XLM-R) and decoder LLMs (e.g., Mistral-7B).
- proposed method comes close to the original models’ performance in cross-lingual and coding tasks while markedly reducing the length of the tokenized sequence, with remaining gap can be quickly closed by continued training on less than 1B tokens
- Finally, it shows that a ZeTT hypernetwork trained for a base LLM can also be applied to fine-tuned variants without extra training.
Background
i) Tokenizers and Embeddings
- Tokenizers operate as a tokenization function T mapping a text to a sequence of elements in the vocabulary V
ii) Embedding Initialization Heuristics
- Prior work transfers LMs to a new tokenizer by initializing embedding parameters via a heuristic, then continuing to train the embeddings
iii) Heuristic-Free Tokenizer Transfer
- prior work has investigated heuristics to initialize the embedding layer, there is also research into changing the training procedure to facilitate n-shot tokenizer transfer.
iv) Embedding Prediction Hypernetworks
- Hypernetworks are networks that predict the parameters of another network [2].
- Prior work uses neural networks to predict embeddings for out-of-vocabulary [3] or rare words[4] of word embedding models[5] extend this approach to predict embeddings for rare words in BERT models [6].These methods can also be viewed as embedding prediction hypernetworks.
- In contrasts, the hypernetwork authors of [1] propose (i) approaches the more general problem of transferring to an arbitrary tokenizer, instead of extending the original tokenizer and (ii) can be applied to encoder, decoder, and encoder-decoder LMs, that is, it is objective-agnostic.
Methodology
i) Hypernetwork Training
- aim to find parameters θ of a hypernetwork Hθ : (Vb, Tb) → ϕb for some pretrained LM.
- Figure below shows the flow of information with hypernetwork predicting input and output embeddings based on the tokenizer.

a) Defining Distributions over Texts and Tokenizers
- sample texts uniformly from the training corpus
- Since tokenizer sampling is not as trivial, thereby author focused on building a distribution over tokenizers (Vb, Tb) with high variance to encourage generalization to unseen tokenizers
- introduce a procedure to sample a diverse set of UnigramLM tokenizers.
Algorithm followed is as in figure below and described afterwards:

- initially fill a queue q with n texts sampled randomly from the training corpus and, at every step in the training loop, push the m texts in the current batch and remove the m least recently added texts.
- then compute all substrings t up to length l and their frequency in q.
- add Gaussian noise to the frequencies to arrive at a final score p(t) for every token t.
- Finally, we assemble the tokenizer by taking the top k tokens with the highest p(t) as the vocabulary and UnigramLM parametrized by p(t) as the tokenization function.
- Another thing to take note of, texts and the tokenizer are sampled dependently: the batch of m texts used for training is a subset of the n texts used for sampling the tokenizer. If they were sampled independently, the probability for a token to occur would be p(token) ∝ p(token ∈ Vb) × p(token ∈ x).
b) MIMICK-Style Warmup & Auxiliary Loss
- included a warmup stage where authors trained the hypernetwork to mimic the embedding parameters of the original tokenizer, akin to MIMICK [3].
- warmup stage is substantially quicker than the main stage because there is no need to propagate through the main model
- Afterwards, authors added an auxiliary loss, which, for every token in the sampled vocabulary Vb that also exists in the original vocabulary Va, penalizes the distance to the corresponding embedding in ϕa.
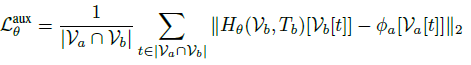
- This penalizes drift from the warmup stage. Combining it with the main loss yields the final loss.
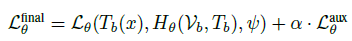
- hyperparameter α weighs the contribution of the auxiliary loss. Since Hθ(Vb, Tb) is also required for the main loss, it requires negligible extra computation.
- The auxiliary loss is necessary especially for models with separate input and output embedding matrices.
ii) Hypernetwork Architecture
- As outlined in figure below, the hypernetwork consists of a language model HLMθ learning to compose embeddings under the original tokenization into a new embedding and amortizes over the tokenization function.
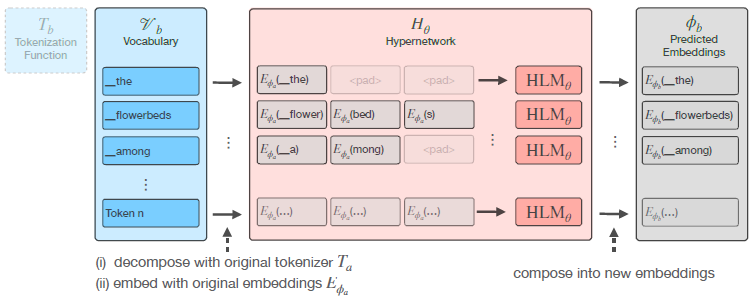
- authors represent the new tokens tb ∈ Vb by decomposing them using the original tokenization function Ta, and embedding them with the original embeddings Eϕa.
- sequence of embeddings is passed through multiple Transformer layers, plus a separate prediction head for the input embeddings and output embeddings ϕin b and ϕoutb .
- hypernetwork thus consists of another language model referred to as HLMθ which is applied separately for every token.
- HLMθ can be thought of as learning how to compose the sequence of tokens Ta(t) — which any given token is decomposed into — into one embedding
- tokenization function was not taken into account, and instead diverse tokenizers were sampled during the training process, aiming for the hypernetwork to learn to produce a single embedding suitable to a wide variety of different tokenization functions.
a) On Token Decomposition
- input to the hypernetwork consists of the sequence of tokens Ta(t) that any given token is decomposed into, which is not always trivial.
- To solve the issue of token t being any arbitrary sequence of bytes, authors introduce a procedure to convert tokenizers to the byte level by adding a small amount of extra tokens to the vocabulary, thereby guaranteeing that Ta can decompose arbitrary tokens.
Experiments
i) Setup
a) Data
- English subset of the MADLAD-400 corpus and code from the StarCoder data was used for hypernetwork training
- For the multilingual hypernetwork, authors used a subset of 26 of the languages used in XGLM with data from MADLAD-400 languages using a multinomial distribution
- For the n-shot experiments, authors also trained on the StarCoder data, but substitute the English section of the MADLAD-400 corpus for Flan v2
b) Evaluation
- PiQA , HellaSwag, BoolQ , MMLU and the “easy” subset of ARC for evaluation in English and the synthesis task of HumanEvalPack for coding evaluation
- For multilingual evaluation, authors used XNLI, XCOPA and MMLU as machine-translated by [7].
c) Models
- Mistral-7B was used as the main decoder-style language model and XLM-R as a representative of encoder-style models.
d) Tokenizers
- authors transfer models to the GPT2 tokenizer for evaluation on natural language benchmarks and to the StarCoder tokenizer for evaluation on code benchmarks.
- For multilingual evaluation, authors train language-specific monolingual tokenizers with a vocabulary size of 50k using SentencePiece and evaluate transfer to these.
e) Hypernetwork training
- authors train the hypernetwork for 200k gradient update steps (10k of which are MIMICK-style warmup) with a batch size of 128 tokens and a sequence length of 128.
- For the multilingual decoder-style models, authors start from the English + Code checkpoint and forgo MIMICK-style warmup, keeping other hyperparameters unchanged.
- authors use a RoBERTa-style architecture i.e. bidirectional attention and Post-LayerNorm Transformer layers , but use a feedforward dimension of 2x the hidden dimension (instead of RoBERTa’s 4x) for the hypernetwork.
ii) Zero-Shot and n-shot Results
- Table below shows Accuracy on XNLI when reusing adapters trained for the original XLM-R model with new zero-shot transferred language-specific tokenizers. Also shown are the absolute change in accuracy from applying our hypernetwork (Δaccuracy) and the average decrease in token length of the language-specific tokenizers over the original tokenizer (Δlength).
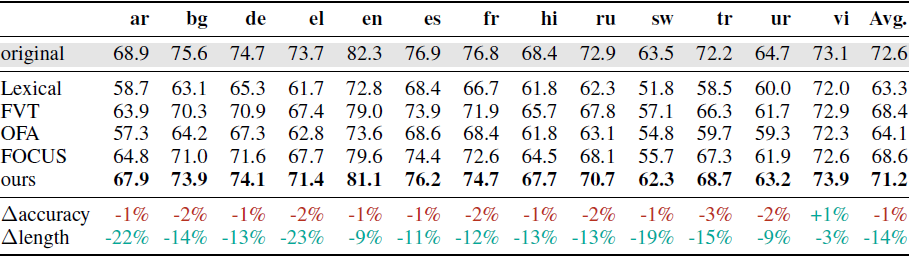
- As it can be observed from results above, hypernetwork consistently outperforms all baselines and preserves accuracy to 1% on average, losing 3% in the worst case and improving by 1% in the best case, while sequences are on average 14% shorter for the language-specific tokenizers; inference is thus more than 16% faster.
- Table below shows Performance of Mistral-7B-v0.1 after zero-shot and n-shot tokenizer transfer (training on 800M tokens), where transfer to the GPT2 tokenizer was evaluated on natural language benchmarks and transfer to the StarCoder tokenizer on HumanEvalPack.
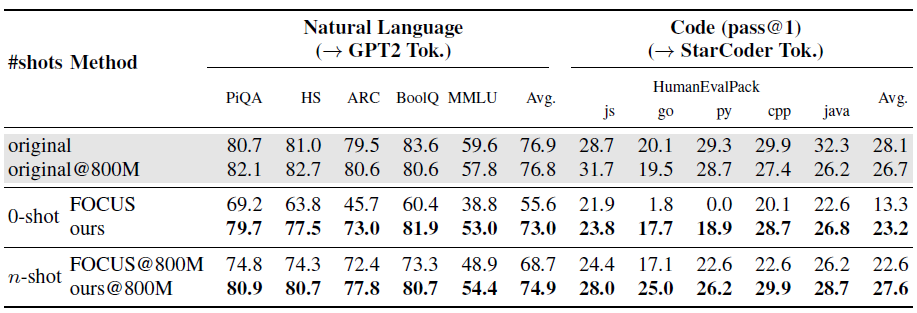
- Results above shows that ZeTT is more challenging in the decoder case: FOCUS [9] performs roughly random in the worst case (-23.2% on BoolQ) and is reduced to 0% pass@1 on HumanEval in Python
- continued training with the original tokenizer slightly degrades performance on average, possibly due to a higher-quality data mix used for pretraining Mistral-7B, whereas authors used public data sources
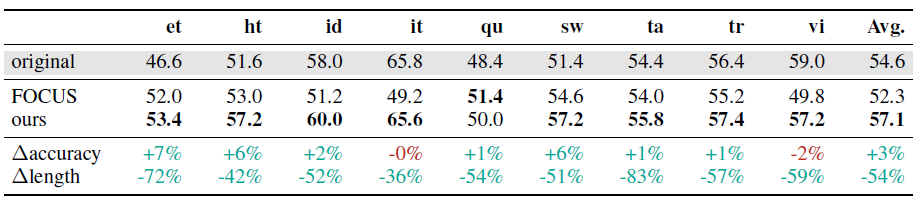
- Table below shows Accuracy of Mistral-7B on XCOPA with language-specific tokenizers zero-shot transferred via FOCUS[9] and our hypernetwork. The standard errors are between 2.1% and 2.3%.
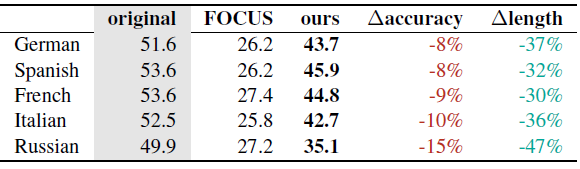
- Table below shows 5-shot accuracy of Mistral-7B on multilingual MMLU with the original tokenizer and language-specific tokenizers zero-shot transferred via FOCUS and ZeTT hypernetwork.
- On XCOPA, the hypernetwork on average improves performance over the original model, while also more than halving sequence length. XCOPA performance is close to random in some languages (e.g. Southern Quechua (qu) and Estonian (et))
- For evaluation on multilingual MMLU, although the hypernetwork clearly outperforms FOCUS (which performs close to random), there is still a substantial gap to the original model; this could presumably be fixed via continued training.
iii) Applying a Hypernetwork trained for a Base Model to Fine-Tuned Models
- As shown in previous sections, it is established that hypernetwork can be successfully applied for transferring the tokenizer of the base model it was trained on.
- But for fine-tuned models question need to be asked is that “Given a hypernetwork trained for a base model, can we apply this hypernetwork to fine-tuned versions of the same model without any extra training?”
- First, authors observed that the embedding space of a fine-tuned model is compatible with that of the base model: the embeddings of the fine-tuned Mistral-7B-Instruct-v0.1 have an average cosine similarity of 98.6% to the corresponding embedding in the base model while the average cosine similarity of the mean embedding vector is 17.4%
- By evaluating Mistral-7B-Instruct-v0.1 transferred to the GPT2 tokenizer on the corrected version of MT-Bench, authors established that predictions of a hypernetwork trained for a base model can thus be used out-of-the-box with fine-tuned models.
- For n-shot transfer, since authors train the full model , they also needed a way to transfer the non-embedding parameters; which they achieve via Task Arithmetic[8]
- Table below shows Single model rating results on MT-Bench of transferring Mistral-7B-Instruct-v0.1 to the GPT2 tokenizer using the hypernetwork trained for the base Mistral-7B model, using gpt-3.5-turbo-1106 as a judge. orig. is the original fine-tuned model, base the model with the same tokenizer but embeddings substituted for the base models’ embeddings. λ is the scaling factor for the weight differences in Task Arithmetic.

- transferred fine-tuned model performs well, coming within approx. 0.5 score of the original model, further the fine-tuned model with the original tokenizer performs better when using the embeddings of the (not fine-tuned) base model.
Results Discussion
i) Converting tokenizers to byte-level
- tokenizers need to be converted to the byte level to ensure that token decomposition is always possible, which seems trivial as just bytes need to be added to vocabulary, but BPE is an exception there, which needed change of the atomic units on which merges are defined from characters to bytes
- That issues was resolved by adding merges to assemble the characters used by the tokenizer from their constituent bytes to the beginning of the merge table.
- success was measured of the conversion to byte level as the probability that, given some pretoken sampled from a corpus, this pretoken results in the same token sequence in the original and the converted tokenizer.
- Table below shows Probability of pretokens sampled from the English MADLAD-400 data to be tokenized equivalently to the original tokenization when converting the tokenizer to byte-level (To Byte-Level) or to UnigramLM (Unigramify). Also shown is the LMs bits-per-character when applying the original vs. the corresponding UnigramLM tokenizer. Bits-per-character can not be measured for conversion to byte-level since extra tokens are added in this process
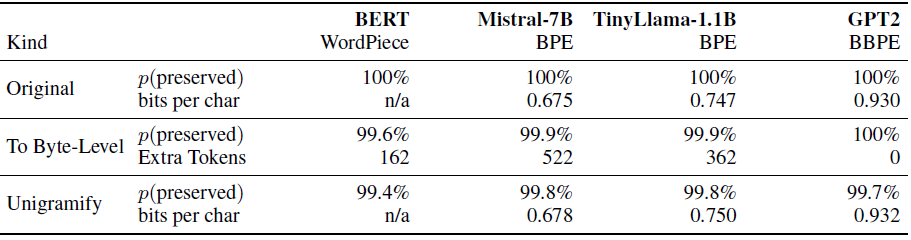
ii) Converting tokenizers to UnigramLM
- introduced a procedure to convert arbitrary tokenizers to tokenizers using UnigramLM as the tokenization function, referred to as unigramifying.
- Unigramifying allows to check by using the UnigramLM parametrization with scores distributed as Gaussians we can cover a sufficiently diverse distribution of tokenizers to enable the hypernetwork to generalize to
- Results in table above in previous subsection indicates that distribution of tokenizers is sufficiently diverse and unigramifying results in minimal performance degradation when substituting the original tokenizer with the corresponding UnigramLM tokenizer
iii) What is the effect of amortizing over the tokenization function?
- ZeTT ‘amortize’ over the tokenization function, that is, the tokenization function is not an input to its hypernetwork
- Table below shows Bits-per-character of GPT2 with the original tokenizer and the tokenization function being original (left), unigramified (middle) and UnigramLM with scores set to the substring frequency of the tokens (right). We compare the original embeddings with embeddings predicted from our hypernetwork, with or without Gaussian noise in the sampling process.

- Results above shows that predicted amortized embeddings are robust to the choice of tokenization function, like the set of embeddings predicted for the GPT2 vocabulary has low bits-per-character for both the original GPT2 tokenization function and a different UnigramLM tokenization function with scores based on token frequencies.
- This is not the case for the original GPT2 embeddings: while they (as expected) perform well with the original GPT2 tokenizer, there is significant performance degradation when switching to the frequency-based UnigramLM tokenization function
iv) Analyzing computational overhead of the hypernetwork
- Table below shows Parameter count and FLOPs estimates for our hypernetwork (and the corresponding main model) in different setups. The relatively lower computational cost compared to parameter count is mainly due to forgoing de-embedding which contributes significantly to FLOPs.
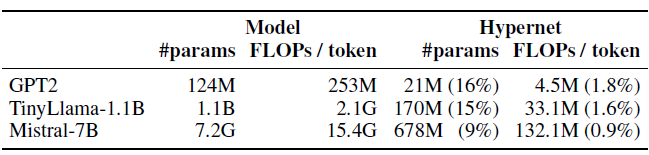
- from results above, authors observed that hypernetwork size of three layers is sufficient, regardless of model size, so the relative overhead decreases with increased amounts of layers in the main model.
Conclusion
- established Zero-Shot Tokenizer Transfer (ZeTT), the difficult problem of transferring language models to a new tokenizer without any training
- found that prior heuristics for embedding initialization provide a first baseline for ZeTT, but fall short in many cases.
- To establish a much stronger baseline, authors introduced a hypernetwork-based approach that closes the gap to a large extent, and can be further improved via continued training on a few (<1B) tokens.
- Due to preserving the embedding space of the original model, ZeTT can be applied to e.g. reusing adapters trained for the original model with a different tokenizer, and to transferring fine-tuned models to a new tokenizer using a hypernetwork trained for the base model
Paper: https://arxiv.org/abs/2405.07883
Code and Models: https://github.com/bminixhofer/zett
References:
- Zero-Shot Tokenizer Transfer by Minixhofer et al. arXiv:2405.07883
- Hypernetworks. In International Conference on Learning Representations, by Ha et al. URL https://openreview.net/forum?id=rkpACe1lx.
- Mimicking word embeddings using subword rnns. by Pinter et al. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing
- Attentive mimicking: Better word embeddings by attending to informative by Schick et al. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics
- Efficient estimation of word representations in vector space by Mikolov et al. arXiv:1301.3781
6. BERT: Pre-training of deep bidirectional transformers for language understanding. by Devlin et al. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
7. Okapi: Instruction-tuned large language models in multiple languages with reinforcement learning from human feedback.by Lai et al., Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
8. Editing models with task arithmetic. In The Eleventh International Conference on Learning Representations, by Ilharco et al. 2023. URL https://openreview.net/forum?id=6t0Kwf8-jrj.
9. FOCUS: Effective embedding initialization for monolingual specialization of multilingual models. by Dobler et al. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing