CTC forced alignment API tutorial — Torchaudio 2.2.0.dev20240509 documentation
Excerpt
Author: Xiaohui Zhang, Moto Hira
Author: Xiaohui Zhang, Moto Hira
The forced alignment is a process to align transcript with speech. This tutorial shows how to align transcripts to speech using torchaudio.functional.forced_align() which was developed along the work of Scaling Speech Technology to 1,000+ Languages.
forced_align() has custom CPU and CUDA implementations which are more performant than the vanilla Python implementation above, and are more accurate. It can also handle missing transcript with special <star> token.
There is also a high-level API, torchaudio.pipelines.Wav2Vec2FABundle, which wraps the pre/post-processing explained in this tutorial and makes it easy to run forced-alignments. Forced alignment for multilingual data uses this API to illustrate how to align non-English transcripts.
Preparation
<span></span>2.4.0.dev20240508
2.2.0.dev20240509
<span></span><span>import</span> <span>IPython</span>
<span>import</span> <span>matplotlib.pyplot</span> <span>as</span> <span>plt</span>
<span>import</span> <span>torchaudio.functional</span> <span>as</span> <span>F</span>
First we prepare the speech data and the transcript we area going to use.
<span></span><a href="https://docs.python.org/3/library/stdtypes.html#str" title="builtins.str"><span>SPEECH_FILE</span></a> <span>=</span> <span>torchaudio</span><span>.</span><span>utils</span><span>.</span><span>download_asset</span><span>(</span><span>"tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"</span><span>)</span>
<a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>waveform</span></a><span>,</span> <span>_</span> <span>=</span> <span>torchaudio</span><span>.</span><span>load</span><span>(</span><a href="https://docs.python.org/3/library/stdtypes.html#str" title="builtins.str"><span>SPEECH_FILE</span></a><span>)</span>
<a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>TRANSCRIPT</span></a> <span>=</span> <span>"i had that curiosity beside me at this moment"</span><span>.</span><span>split</span><span>()</span>
Generating emissions
forced_align() takes emission and token sequences and outputs timestaps of the tokens and their scores.
Emission reperesents the frame-wise probability distribution over tokens, and it can be obtained by passing waveform to an acoustic model.
Tokens are numerical expression of transcripts. There are many ways to tokenize transcripts, but here, we simply map alphabets into integer, which is how labels were constructed when the acoustice model we are going to use was trained.
We will use a pre-trained Wav2Vec2 model, torchaudio.pipelines.MMS_FA, to obtain emission and tokenize the transcript.
<span></span>Downloading: "https://dl.fbaipublicfiles.com/mms/torchaudio/ctc_alignment_mling_uroman/model.pt" to /root/.cache/torch/hub/checkpoints/model.pt
0%| | 0.00/1.18G [00:00<?, ?B/s]
2%|1 | 18.5M/1.18G [00:00<00:06, 189MB/s]
3%|3 | 36.6M/1.18G [00:00<00:06, 184MB/s]
5%|5 | 60.8M/1.18G [00:00<00:05, 215MB/s]
7%|6 | 82.5M/1.18G [00:00<00:05, 220MB/s]
9%|8 | 104M/1.18G [00:00<00:06, 191MB/s]
10%|# | 122M/1.18G [00:00<00:06, 180MB/s]
12%|#1 | 140M/1.18G [00:00<00:06, 165MB/s]
13%|#3 | 158M/1.18G [00:00<00:06, 173MB/s]
15%|#4 | 176M/1.18G [00:01<00:06, 177MB/s]
16%|#6 | 194M/1.18G [00:01<00:06, 163MB/s]
17%|#7 | 210M/1.18G [00:01<00:06, 158MB/s]
19%|#8 | 225M/1.18G [00:01<00:06, 158MB/s]
20%|## | 244M/1.18G [00:01<00:06, 167MB/s]
22%|##1 | 260M/1.18G [00:01<00:06, 150MB/s]
23%|##3 | 280M/1.18G [00:01<00:05, 164MB/s]
25%|##4 | 296M/1.18G [00:01<00:05, 165MB/s]
26%|##5 | 312M/1.18G [00:01<00:06, 153MB/s]
27%|##7 | 327M/1.18G [00:02<00:05, 154MB/s]
28%|##8 | 343M/1.18G [00:02<00:05, 158MB/s]
30%|##9 | 360M/1.18G [00:02<00:05, 164MB/s]
31%|###1 | 376M/1.18G [00:02<00:05, 156MB/s]
33%|###2 | 391M/1.18G [00:02<00:05, 155MB/s]
34%|###4 | 410M/1.18G [00:02<00:05, 166MB/s]
36%|###5 | 428M/1.18G [00:02<00:04, 168MB/s]
37%|###7 | 446M/1.18G [00:02<00:04, 173MB/s]
38%|###8 | 462M/1.18G [00:02<00:04, 158MB/s]
40%|###9 | 478M/1.18G [00:03<00:04, 158MB/s]
42%|####1 | 500M/1.18G [00:03<00:04, 178MB/s]
43%|####3 | 520M/1.18G [00:03<00:03, 188MB/s]
45%|####4 | 539M/1.18G [00:03<00:03, 186MB/s]
46%|####6 | 556M/1.18G [00:03<00:03, 181MB/s]
48%|####7 | 574M/1.18G [00:03<00:03, 167MB/s]
49%|####9 | 590M/1.18G [00:03<00:03, 161MB/s]
50%|##### | 606M/1.18G [00:03<00:04, 145MB/s]
52%|#####1 | 620M/1.18G [00:03<00:04, 137MB/s]
53%|#####2 | 636M/1.18G [00:04<00:04, 145MB/s]
54%|#####4 | 654M/1.18G [00:04<00:03, 157MB/s]
56%|#####5 | 672M/1.18G [00:04<00:03, 165MB/s]
57%|#####7 | 689M/1.18G [00:04<00:03, 162MB/s]
59%|#####8 | 704M/1.18G [00:04<00:03, 156MB/s]
60%|#####9 | 720M/1.18G [00:04<00:03, 139MB/s]
61%|###### | 733M/1.18G [00:04<00:05, 91.5MB/s]
62%|######1 | 744M/1.18G [00:05<00:05, 92.4MB/s]
63%|######2 | 754M/1.18G [00:05<00:04, 95.6MB/s]
64%|######3 | 766M/1.18G [00:05<00:04, 102MB/s]
65%|######4 | 777M/1.18G [00:05<00:04, 101MB/s]
66%|######5 | 788M/1.18G [00:05<00:04, 104MB/s]
66%|######6 | 799M/1.18G [00:05<00:04, 98.8MB/s]
68%|######7 | 814M/1.18G [00:05<00:03, 112MB/s]
69%|######8 | 826M/1.18G [00:05<00:03, 117MB/s]
70%|######9 | 840M/1.18G [00:05<00:03, 122MB/s]
71%|#######1 | 856M/1.18G [00:06<00:02, 134MB/s]
72%|#######2 | 872M/1.18G [00:06<00:02, 143MB/s]
74%|#######3 | 885M/1.18G [00:06<00:02, 126MB/s]
75%|#######4 | 898M/1.18G [00:06<00:02, 111MB/s]
76%|#######5 | 914M/1.18G [00:06<00:02, 125MB/s]
77%|#######7 | 928M/1.18G [00:06<00:02, 129MB/s]
78%|#######8 | 940M/1.18G [00:06<00:02, 125MB/s]
79%|#######9 | 953M/1.18G [00:06<00:02, 119MB/s]
80%|######## | 966M/1.18G [00:06<00:01, 126MB/s]
82%|########1 | 985M/1.18G [00:07<00:01, 145MB/s]
83%|########3 | 0.98G/1.18G [00:07<00:01, 144MB/s]
84%|########4 | 0.99G/1.18G [00:07<00:01, 155MB/s]
86%|########5 | 1.01G/1.18G [00:07<00:01, 150MB/s]
87%|########6 | 1.02G/1.18G [00:07<00:01, 134MB/s]
88%|########8 | 1.03G/1.18G [00:07<00:01, 129MB/s]
89%|########9 | 1.05G/1.18G [00:07<00:00, 142MB/s]
91%|######### | 1.07G/1.18G [00:07<00:00, 145MB/s]
92%|#########1| 1.08G/1.18G [00:07<00:00, 143MB/s]
93%|#########3| 1.10G/1.18G [00:08<00:00, 157MB/s]
95%|#########5| 1.12G/1.18G [00:08<00:00, 172MB/s]
97%|#########6| 1.14G/1.18G [00:08<00:00, 186MB/s]
98%|#########8| 1.16G/1.18G [00:08<00:00, 186MB/s]
100%|#########9| 1.17G/1.18G [00:08<00:00, 177MB/s]
100%|##########| 1.18G/1.18G [00:08<00:00, 149MB/s]
<span></span><span>def</span> <span>plot_emission</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>):</span>
<span>fig</span><span>,</span> <span>ax</span> <span>=</span> <span>plt</span><span>.</span><span>subplots</span><span>()</span>
<span>ax</span><span>.</span><span>imshow</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>.</span><span>cpu</span><span>()</span><span>.</span><span>T</span><span>)</span>
<span>ax</span><span>.</span><span>set_title</span><span>(</span><span>"Frame-wise class probabilities"</span><span>)</span>
<span>ax</span><span>.</span><span>set_xlabel</span><span>(</span><span>"Time"</span><span>)</span>
<span>ax</span><span>.</span><span>set_ylabel</span><span>(</span><span>"Labels"</span><span>)</span>
<span>fig</span><span>.</span><span>tight_layout</span><span>()</span>
<span>plot_emission</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>[</span><span>0</span><span>])</span>
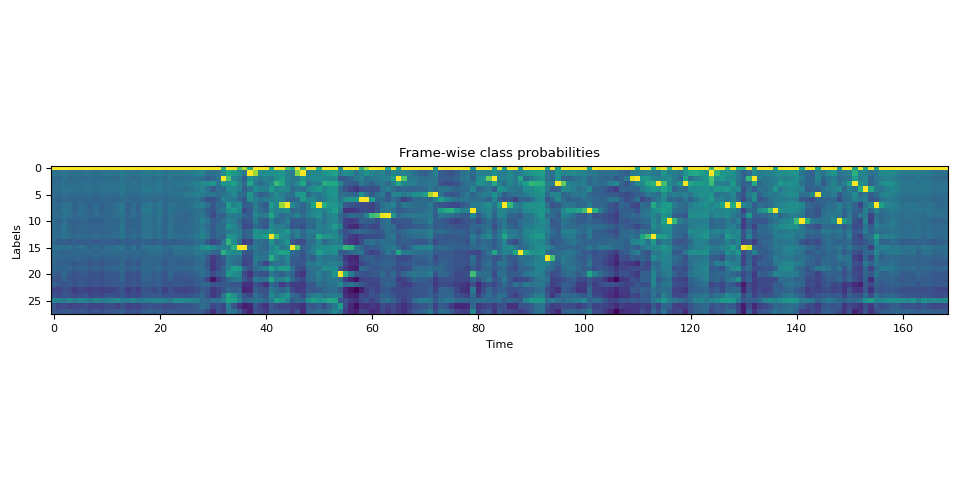
Tokenize the transcript
We create a dictionary, which maps each label into token.
<span></span>-: 0
a: 1
i: 2
e: 3
n: 4
o: 5
u: 6
t: 7
s: 8
r: 9
m: 10
k: 11
l: 12
d: 13
g: 14
h: 15
y: 16
b: 17
p: 18
w: 19
c: 20
v: 21
j: 22
z: 23
f: 24
': 25
q: 26
x: 27
converting transcript to tokens is as simple as
<span></span>2 15 1 13 7 15 1 7 20 6 9 2 5 8 2 7 16 17 3 8 2 13 3 10 3 1 7 7 15 2 8 10 5 10 3 4 7
Computing alignments
Frame-level alignments
Now we call TorchAudio’s forced alignment API to compute the frame-level alignment. For the detail of function signature, please refer to forced_align().
<span></span><span>def</span> <span>align</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>,</span> <span>tokens</span><span>):</span>
<span>targets</span> <span>=</span> <a href="https://pytorch.org/docs/stable/generated/torch.tensor.html#torch.tensor" title="torch.tensor"><span>torch</span><span>.</span><span>tensor</span></a><span>([</span><span>tokens</span><span>],</span> <span>dtype</span><span>=</span><a href="https://pytorch.org/docs/stable/tensor_attributes.html#torch.dtype" title="torch.dtype"><span>torch</span><span>.</span><span>int32</span></a><span>,</span> <a href="https://pytorch.org/docs/stable/tensor_attributes.html#torch.device" title="torch.device"><span>device</span></a><span>=</span><a href="https://pytorch.org/docs/stable/tensor_attributes.html#torch.device" title="torch.device"><span>device</span></a><span>)</span>
<span>alignments</span><span>,</span> <span>scores</span> <span>=</span> <span>F</span><span>.</span><span>forced_align</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>,</span> <span>targets</span><span>,</span> <span>blank</span><span>=</span><span>0</span><span>)</span>
<span>alignments</span><span>,</span> <span>scores</span> <span>=</span> <span>alignments</span><span>[</span><span>0</span><span>],</span> <span>scores</span><span>[</span><span>0</span><span>]</span> <span># remove batch dimension for simplicity</span>
<span>scores</span> <span>=</span> <span>scores</span><span>.</span><span>exp</span><span>()</span> <span># convert back to probability</span>
<span>return</span> <span>alignments</span><span>,</span> <span>scores</span>
<a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>aligned_tokens</span></a><span>,</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>alignment_scores</span></a> <span>=</span> <span>align</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>,</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>tokenized_transcript</span></a><span>)</span>
Now let’s look at the output.
<span></span> 0: 0 [-], 1.00
1: 0 [-], 1.00
2: 0 [-], 1.00
3: 0 [-], 1.00
4: 0 [-], 1.00
5: 0 [-], 1.00
6: 0 [-], 1.00
7: 0 [-], 1.00
8: 0 [-], 1.00
9: 0 [-], 1.00
10: 0 [-], 1.00
11: 0 [-], 1.00
12: 0 [-], 1.00
13: 0 [-], 1.00
14: 0 [-], 1.00
15: 0 [-], 1.00
16: 0 [-], 1.00
17: 0 [-], 1.00
18: 0 [-], 1.00
19: 0 [-], 1.00
20: 0 [-], 1.00
21: 0 [-], 1.00
22: 0 [-], 1.00
23: 0 [-], 1.00
24: 0 [-], 1.00
25: 0 [-], 1.00
26: 0 [-], 1.00
27: 0 [-], 1.00
28: 0 [-], 1.00
29: 0 [-], 1.00
30: 0 [-], 1.00
31: 0 [-], 1.00
32: 2 [i], 1.00
33: 0 [-], 1.00
34: 0 [-], 1.00
35: 15 [h], 1.00
36: 15 [h], 0.93
37: 1 [a], 1.00
38: 0 [-], 0.96
39: 0 [-], 1.00
40: 0 [-], 1.00
41: 13 [d], 1.00
42: 0 [-], 1.00
43: 0 [-], 0.97
44: 7 [t], 1.00
45: 15 [h], 1.00
46: 0 [-], 0.98
47: 1 [a], 1.00
48: 0 [-], 1.00
49: 0 [-], 1.00
50: 7 [t], 1.00
51: 0 [-], 1.00
52: 0 [-], 1.00
53: 0 [-], 1.00
54: 20 [c], 1.00
55: 0 [-], 1.00
56: 0 [-], 1.00
57: 0 [-], 1.00
58: 6 [u], 1.00
59: 6 [u], 0.96
60: 0 [-], 1.00
61: 0 [-], 1.00
62: 0 [-], 0.53
63: 9 [r], 1.00
64: 0 [-], 1.00
65: 2 [i], 1.00
66: 0 [-], 1.00
67: 0 [-], 1.00
68: 0 [-], 1.00
69: 0 [-], 1.00
70: 0 [-], 1.00
71: 0 [-], 0.96
72: 5 [o], 1.00
73: 0 [-], 1.00
74: 0 [-], 1.00
75: 0 [-], 1.00
76: 0 [-], 1.00
77: 0 [-], 1.00
78: 0 [-], 1.00
79: 8 [s], 1.00
80: 0 [-], 1.00
81: 0 [-], 1.00
82: 0 [-], 0.99
83: 2 [i], 1.00
84: 0 [-], 1.00
85: 7 [t], 1.00
86: 0 [-], 1.00
87: 0 [-], 1.00
88: 16 [y], 1.00
89: 0 [-], 1.00
90: 0 [-], 1.00
91: 0 [-], 1.00
92: 0 [-], 1.00
93: 17 [b], 1.00
94: 0 [-], 1.00
95: 3 [e], 1.00
96: 0 [-], 1.00
97: 0 [-], 1.00
98: 0 [-], 1.00
99: 0 [-], 1.00
100: 0 [-], 1.00
101: 8 [s], 1.00
102: 0 [-], 1.00
103: 0 [-], 1.00
104: 0 [-], 1.00
105: 0 [-], 1.00
106: 0 [-], 1.00
107: 0 [-], 1.00
108: 0 [-], 1.00
109: 0 [-], 0.64
110: 2 [i], 1.00
111: 0 [-], 1.00
112: 0 [-], 1.00
113: 13 [d], 1.00
114: 3 [e], 0.85
115: 0 [-], 1.00
116: 10 [m], 1.00
117: 0 [-], 1.00
118: 0 [-], 1.00
119: 3 [e], 1.00
120: 0 [-], 1.00
121: 0 [-], 1.00
122: 0 [-], 1.00
123: 0 [-], 1.00
124: 1 [a], 1.00
125: 0 [-], 1.00
126: 0 [-], 1.00
127: 7 [t], 1.00
128: 0 [-], 1.00
129: 7 [t], 1.00
130: 15 [h], 1.00
131: 0 [-], 0.79
132: 2 [i], 1.00
133: 0 [-], 1.00
134: 0 [-], 1.00
135: 0 [-], 1.00
136: 8 [s], 1.00
137: 0 [-], 1.00
138: 0 [-], 1.00
139: 0 [-], 1.00
140: 0 [-], 1.00
141: 10 [m], 1.00
142: 0 [-], 1.00
143: 0 [-], 1.00
144: 5 [o], 1.00
145: 0 [-], 1.00
146: 0 [-], 1.00
147: 0 [-], 1.00
148: 10 [m], 1.00
149: 0 [-], 1.00
150: 0 [-], 1.00
151: 3 [e], 1.00
152: 0 [-], 1.00
153: 4 [n], 1.00
154: 0 [-], 1.00
155: 7 [t], 1.00
156: 0 [-], 1.00
157: 0 [-], 1.00
158: 0 [-], 1.00
159: 0 [-], 1.00
160: 0 [-], 1.00
161: 0 [-], 1.00
162: 0 [-], 1.00
163: 0 [-], 1.00
164: 0 [-], 1.00
165: 0 [-], 1.00
166: 0 [-], 1.00
167: 0 [-], 1.00
168: 0 [-], 1.00
Note
The alignment is expressed in the frame cordinate of the emission, which is different from the original waveform.
It contains blank tokens and repeated tokens. The following is the interpretation of the non-blank tokens.
<span></span><span>31</span><span>:</span> <span>0</span> <span>[</span><span>-</span><span>],</span> <span>1.00</span>
<span>32</span><span>:</span> <span>2</span> <span>[</span><a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>i</span></a><span>],</span> <span>1.00</span> <span>"i"</span> <span>starts</span> <span>and</span> <span>ends</span>
<span>33</span><span>:</span> <span>0</span> <span>[</span><span>-</span><span>],</span> <span>1.00</span>
<span>34</span><span>:</span> <span>0</span> <span>[</span><span>-</span><span>],</span> <span>1.00</span>
<span>35</span><span>:</span> <span>15</span> <span>[</span><span>h</span><span>],</span> <span>1.00</span> <span>"h"</span> <span>starts</span>
<span>36</span><span>:</span> <span>15</span> <span>[</span><span>h</span><span>],</span> <span>0.93</span> <span>"h"</span> <span>ends</span>
<span>37</span><span>:</span> <span>1</span> <span>[</span><span>a</span><span>],</span> <span>1.00</span> <span>"a"</span> <span>starts</span> <span>and</span> <span>ends</span>
<span>38</span><span>:</span> <span>0</span> <span>[</span><span>-</span><span>],</span> <span>0.96</span>
<span>39</span><span>:</span> <span>0</span> <span>[</span><span>-</span><span>],</span> <span>1.00</span>
<span>40</span><span>:</span> <span>0</span> <span>[</span><span>-</span><span>],</span> <span>1.00</span>
<span>41</span><span>:</span> <span>13</span> <span>[</span><span>d</span><span>],</span> <span>1.00</span> <span>"d"</span> <span>starts</span> <span>and</span> <span>ends</span>
<span>42</span><span>:</span> <span>0</span> <span>[</span><span>-</span><span>],</span> <span>1.00</span>
Note
When same token occured after blank tokens, it is not treated as a repeat, but as a new occurrence.
<span></span><span>a</span> <span>a</span> <span>a</span> <span>b</span> <span>-></span> <span>a</span> <span>b</span>
<span>a</span> <span>-</span> <span>-</span> <span>b</span> <span>-></span> <span>a</span> <span>b</span>
<span>a</span> <span>a</span> <span>-</span> <span>b</span> <span>-></span> <span>a</span> <span>b</span>
<span>a</span> <span>-</span> <span>a</span> <span>b</span> <span>-></span> <span>a</span> <span>a</span> <span>b</span>
<span>^^^</span> <span>^^^</span>
Token-level alignments
Next step is to resolve the repetation, so that each alignment does not depend on previous alignments. torchaudio.functional.merge_tokens() computes the TokenSpan object, which represents which token from the transcript is present at what time span.
<span></span>Token Time Score
i [ 32, 33) 1.00
h [ 35, 37) 0.96
a [ 37, 38) 1.00
d [ 41, 42) 1.00
t [ 44, 45) 1.00
h [ 45, 46) 1.00
a [ 47, 48) 1.00
t [ 50, 51) 1.00
c [ 54, 55) 1.00
u [ 58, 60) 0.98
r [ 63, 64) 1.00
i [ 65, 66) 1.00
o [ 72, 73) 1.00
s [ 79, 80) 1.00
i [ 83, 84) 1.00
t [ 85, 86) 1.00
y [ 88, 89) 1.00
b [ 93, 94) 1.00
e [ 95, 96) 1.00
s [101, 102) 1.00
i [110, 111) 1.00
d [113, 114) 1.00
e [114, 115) 0.85
m [116, 117) 1.00
e [119, 120) 1.00
a [124, 125) 1.00
t [127, 128) 1.00
t [129, 130) 1.00
h [130, 131) 1.00
i [132, 133) 1.00
s [136, 137) 1.00
m [141, 142) 1.00
o [144, 145) 1.00
m [148, 149) 1.00
e [151, 152) 1.00
n [153, 154) 1.00
t [155, 156) 1.00
Word-level alignments
Now let’s group the token-level alignments into word-level alignments.
<span></span><span>def</span> <span>unflatten</span><span>(</span><span>list_</span><span>,</span> <span>lengths</span><span>):</span>
<span>assert</span> <span>len</span><span>(</span><span>list_</span><span>)</span> <span>==</span> <span>sum</span><span>(</span><span>lengths</span><span>)</span>
<a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>i</span></a> <span>=</span> <span>0</span>
<span>ret</span> <span>=</span> <span>[]</span>
<span>for</span> <span>l</span> <span>in</span> <span>lengths</span><span>:</span>
<span>ret</span><span>.</span><span>append</span><span>(</span><span>list_</span><span>[</span><a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>i</span></a> <span>:</span> <a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>i</span></a> <span>+</span> <span>l</span><span>])</span>
<a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>i</span></a> <span>+=</span> <span>l</span>
<span>return</span> <span>ret</span>
<a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>word_spans</span></a> <span>=</span> <span>unflatten</span><span>(</span><a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>token_spans</span></a><span>,</span> <span>[</span><span>len</span><span>(</span><span>word</span><span>)</span> <span>for</span> <span>word</span> <span>in</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>TRANSCRIPT</span></a><span>])</span>
Audio previews
<span></span><span># Compute average score weighted by the span length</span>
<span>def</span> <span>_score</span><span>(</span><span>spans</span><span>):</span>
<span>return</span> <span>sum</span><span>(</span><a href="https://docs.python.org/3/library/functions.html#float" title="builtins.float"><span>s</span><span>.</span><span>score</span></a> <span>*</span> <span>len</span><span>(</span><span>s</span><span>)</span> <span>for</span> <span>s</span> <span>in</span> <span>spans</span><span>)</span> <span>/</span> <span>sum</span><span>(</span><span>len</span><span>(</span><span>s</span><span>)</span> <span>for</span> <span>s</span> <span>in</span> <span>spans</span><span>)</span>
<span>def</span> <span>preview_word</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>waveform</span></a><span>,</span> <span>spans</span><span>,</span> <a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>num_frames</span></a><span>,</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>transcript</span></a><span>,</span> <span>sample_rate</span><span>=</span><span>bundle</span><span>.</span><span>sample_rate</span><span>):</span>
<span>ratio</span> <span>=</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>waveform</span></a><span>.</span><span>size</span><span>(</span><span>1</span><span>)</span> <span>/</span> <a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>num_frames</span></a>
<span>x0</span> <span>=</span> <span>int</span><span>(</span><span>ratio</span> <span>*</span> <span>spans</span><span>[</span><span>0</span><span>]</span><span>.</span><span>start</span><span>)</span>
<span>x1</span> <span>=</span> <span>int</span><span>(</span><span>ratio</span> <span>*</span> <span>spans</span><span>[</span><span>-</span><span>1</span><span>]</span><span>.</span><span>end</span><span>)</span>
<span>print</span><span>(</span><span>f</span><span>"</span><span>{</span><a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>transcript</span></a><span>}</span><span> (</span><span>{</span><span>_score</span><span>(</span><span>spans</span><span>)</span><span>:</span><span>.2f</span><span>}</span><span>): </span><span>{</span><span>x0</span><span> </span><span>/</span><span> </span><span>sample_rate</span><span>:</span><span>.3f</span><span>}</span><span> - </span><span>{</span><span>x1</span><span> </span><span>/</span><span> </span><span>sample_rate</span><span>:</span><span>.3f</span><span>}</span><span> sec"</span><span>)</span>
<span>segment</span> <span>=</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>waveform</span></a><span>[:,</span> <span>x0</span><span>:</span><span>x1</span><span>]</span>
<span>return</span> <span>IPython</span><span>.</span><span>display</span><span>.</span><span>Audio</span><span>(</span><span>segment</span><span>.</span><span>numpy</span><span>(),</span> <span>rate</span><span>=</span><span>sample_rate</span><span>)</span>
<a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>num_frames</span></a> <span>=</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>.</span><span>size</span><span>(</span><span>1</span><span>)</span>
<span></span>['i', 'had', 'that', 'curiosity', 'beside', 'me', 'at', 'this', 'moment']
Your browser does not support the audio element.
<span></span>i (1.00): 0.644 - 0.664 sec
Your browser does not support the audio element.
<span></span>had (0.98): 0.704 - 0.845 sec
Your browser does not support the audio element.
<span></span>that (1.00): 0.885 - 1.026 sec
Your browser does not support the audio element.
<span></span>curiosity (1.00): 1.086 - 1.790 sec
Your browser does not support the audio element.
<span></span>beside (0.97): 1.871 - 2.314 sec
Your browser does not support the audio element.
<span></span>me (1.00): 2.334 - 2.414 sec
Your browser does not support the audio element.
<span></span>at (1.00): 2.495 - 2.575 sec
Your browser does not support the audio element.
<span></span>this (1.00): 2.595 - 2.756 sec
Your browser does not support the audio element.
<span></span>moment (1.00): 2.837 - 3.138 sec
Your browser does not support the audio element.
Visualization
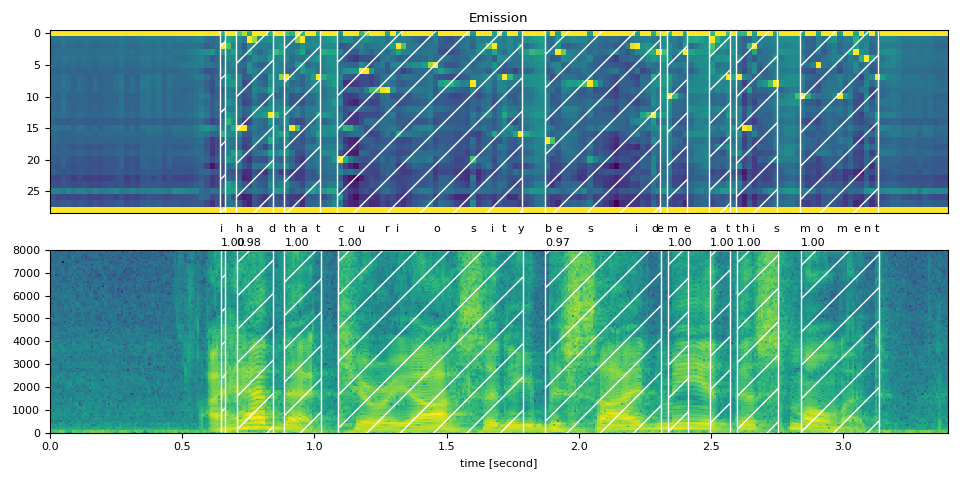
Now let’s look at the alignment result and segment the original speech into words.
<span></span><span>def</span> <span>plot_alignments</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>waveform</span></a><span>,</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>token_spans</span></a><span>,</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>,</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>transcript</span></a><span>,</span> <span>sample_rate</span><span>=</span><span>bundle</span><span>.</span><span>sample_rate</span><span>):</span>
<span>ratio</span> <span>=</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>waveform</span></a><span>.</span><span>size</span><span>(</span><span>1</span><span>)</span> <span>/</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>.</span><span>size</span><span>(</span><span>1</span><span>)</span> <span>/</span> <span>sample_rate</span>
<span>fig</span><span>,</span> <span>axes</span> <span>=</span> <span>plt</span><span>.</span><span>subplots</span><span>(</span><span>2</span><span>,</span> <span>1</span><span>)</span>
<span>axes</span><span>[</span><span>0</span><span>]</span><span>.</span><span>imshow</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>emission</span></a><span>[</span><span>0</span><span>]</span><span>.</span><span>detach</span><span>()</span><span>.</span><span>cpu</span><span>()</span><span>.</span><span>T</span><span>,</span> <span>aspect</span><span>=</span><span>"auto"</span><span>)</span>
<span>axes</span><span>[</span><span>0</span><span>]</span><span>.</span><span>set_title</span><span>(</span><span>"Emission"</span><span>)</span>
<span>axes</span><span>[</span><span>0</span><span>]</span><span>.</span><span>set_xticks</span><span>([])</span>
<span>axes</span><span>[</span><span>1</span><span>]</span><span>.</span><span>specgram</span><span>(</span><a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>waveform</span></a><span>[</span><span>0</span><span>],</span> <span>Fs</span><span>=</span><span>sample_rate</span><span>)</span>
<span>for</span> <span>t_spans</span><span>,</span> <span>chars</span> <span>in</span> <span>zip</span><span>(</span><a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>token_spans</span></a><span>,</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>transcript</span></a><span>):</span>
<span>t0</span><span>,</span> <span>t1</span> <span>=</span> <span>t_spans</span><span>[</span><span>0</span><span>]</span><span>.</span><span>start</span> <span>+</span> <span>0.1</span><span>,</span> <span>t_spans</span><span>[</span><span>-</span><span>1</span><span>]</span><span>.</span><span>end</span> <span>-</span> <span>0.1</span>
<span>axes</span><span>[</span><span>0</span><span>]</span><span>.</span><span>axvspan</span><span>(</span><span>t0</span> <span>-</span> <span>0.5</span><span>,</span> <span>t1</span> <span>-</span> <span>0.5</span><span>,</span> <span>facecolor</span><span>=</span><span>"None"</span><span>,</span> <span>hatch</span><span>=</span><span>"/"</span><span>,</span> <span>edgecolor</span><span>=</span><span>"white"</span><span>)</span>
<span>axes</span><span>[</span><span>1</span><span>]</span><span>.</span><span>axvspan</span><span>(</span><span>ratio</span> <span>*</span> <span>t0</span><span>,</span> <span>ratio</span> <span>*</span> <span>t1</span><span>,</span> <span>facecolor</span><span>=</span><span>"None"</span><span>,</span> <span>hatch</span><span>=</span><span>"/"</span><span>,</span> <span>edgecolor</span><span>=</span><span>"white"</span><span>)</span>
<span>axes</span><span>[</span><span>1</span><span>]</span><span>.</span><span>annotate</span><span>(</span><span>f</span><span>"</span><span>{</span><span>_score</span><span>(</span><span>t_spans</span><span>)</span><span>:</span><span>.2f</span><span>}</span><span>"</span><span>,</span> <span>(</span><span>ratio</span> <span>*</span> <span>t0</span><span>,</span> <span>sample_rate</span> <span>*</span> <span>0.51</span><span>),</span> <span>annotation_clip</span><span>=</span><span>False</span><span>)</span>
<span>for</span> <span>span</span><span>,</span> <span>char</span> <span>in</span> <span>zip</span><span>(</span><span>t_spans</span><span>,</span> <span>chars</span><span>):</span>
<span>t0</span> <span>=</span> <span>span</span><span>.</span><span>start</span> <span>*</span> <span>ratio</span>
<span>axes</span><span>[</span><span>1</span><span>]</span><span>.</span><span>annotate</span><span>(</span><span>char</span><span>,</span> <span>(</span><span>t0</span><span>,</span> <span>sample_rate</span> <span>*</span> <span>0.55</span><span>),</span> <span>annotation_clip</span><span>=</span><span>False</span><span>)</span>
<span>axes</span><span>[</span><span>1</span><span>]</span><span>.</span><span>set_xlabel</span><span>(</span><span>"time [second]"</span><span>)</span>
<span>axes</span><span>[</span><span>1</span><span>]</span><span>.</span><span>set_xlim</span><span>([</span><span>0</span><span>,</span> <span>None</span><span>])</span>
<span>fig</span><span>.</span><span>tight_layout</span><span>()</span>
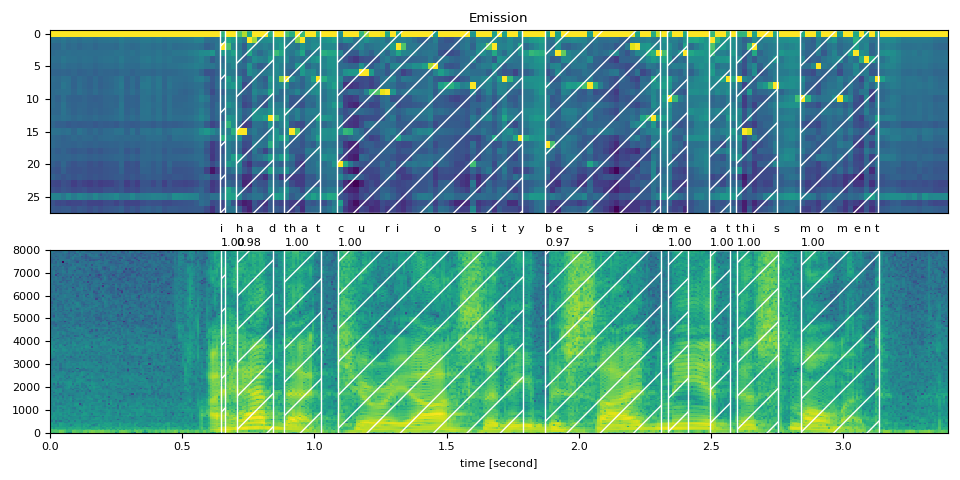
Inconsistent treatment of blank token
When splitting the token-level alignments into words, you will notice that some blank tokens are treated differently, and this makes the interpretation of the result somehwat ambigious.
This is easy to see when we plot the scores. The following figure shows word regions and non-word regions, with the frame-level scores of non-blank tokens.
<span></span><span>def</span> <span>plot_scores</span><span>(</span><a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>word_spans</span></a><span>,</span> <span>scores</span><span>):</span>
<span>fig</span><span>,</span> <span>ax</span> <span>=</span> <span>plt</span><span>.</span><span>subplots</span><span>()</span>
<span>span_xs</span><span>,</span> <span>span_hs</span> <span>=</span> <span>[],</span> <span>[]</span>
<span>ax</span><span>.</span><span>axvspan</span><span>(</span><a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>word_spans</span></a><span>[</span><span>0</span><span>][</span><span>0</span><span>]</span><span>.</span><span>start</span> <span>-</span> <span>0.05</span><span>,</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>word_spans</span></a><span>[</span><span>-</span><span>1</span><span>][</span><span>-</span><span>1</span><span>]</span><span>.</span><span>end</span> <span>+</span> <span>0.05</span><span>,</span> <span>facecolor</span><span>=</span><span>"paleturquoise"</span><span>,</span> <span>edgecolor</span><span>=</span><span>"none"</span><span>,</span> <span>zorder</span><span>=-</span><span>1</span><span>)</span>
<span>for</span> <span>t_span</span> <span>in</span> <a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>word_spans</span></a><span>:</span>
<span>for</span> <span>span</span> <span>in</span> <span>t_span</span><span>:</span>
<span>for</span> <a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>t</span></a> <span>in</span> <span>range</span><span>(</span><span>span</span><span>.</span><span>start</span><span>,</span> <span>span</span><span>.</span><span>end</span><span>):</span>
<span>span_xs</span><span>.</span><span>append</span><span>(</span><a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>t</span></a> <span>+</span> <span>0.5</span><span>)</span>
<span>span_hs</span><span>.</span><span>append</span><span>(</span><span>scores</span><span>[</span><a href="https://docs.python.org/3/library/functions.html#int" title="builtins.int"><span>t</span></a><span>]</span><span>.</span><span>item</span><span>())</span>
<span>ax</span><span>.</span><span>annotate</span><span>(</span><a href="https://docs.python.org/3/library/stdtypes.html#tuple" title="builtins.tuple"><span>LABELS</span></a><span>[</span><span>span</span><span>.</span><span>token</span><span>],</span> <span>(</span><span>span</span><span>.</span><span>start</span><span>,</span> <span>-</span><span>0.07</span><span>))</span>
<span>ax</span><span>.</span><span>axvspan</span><span>(</span><span>t_span</span><span>[</span><span>0</span><span>]</span><span>.</span><span>start</span> <span>-</span> <span>0.05</span><span>,</span> <span>t_span</span><span>[</span><span>-</span><span>1</span><span>]</span><span>.</span><span>end</span> <span>+</span> <span>0.05</span><span>,</span> <span>facecolor</span><span>=</span><span>"mistyrose"</span><span>,</span> <span>edgecolor</span><span>=</span><span>"none"</span><span>,</span> <span>zorder</span><span>=-</span><span>1</span><span>)</span>
<span>ax</span><span>.</span><span>bar</span><span>(</span><span>span_xs</span><span>,</span> <span>span_hs</span><span>,</span> <span>color</span><span>=</span><span>"lightsalmon"</span><span>,</span> <span>edgecolor</span><span>=</span><span>"coral"</span><span>)</span>
<span>ax</span><span>.</span><span>set_title</span><span>(</span><span>"Frame-level scores and word segments"</span><span>)</span>
<span>ax</span><span>.</span><span>set_ylim</span><span>(</span><span>-</span><span>0.1</span><span>,</span> <span>None</span><span>)</span>
<span>ax</span><span>.</span><span>grid</span><span>(</span><span>True</span><span>,</span> <span>axis</span><span>=</span><span>"y"</span><span>)</span>
<span>ax</span><span>.</span><span>axhline</span><span>(</span><span>0</span><span>,</span> <span>color</span><span>=</span><span>"black"</span><span>)</span>
<span>fig</span><span>.</span><span>tight_layout</span><span>()</span>
<span>plot_scores</span><span>(</span><a href="https://docs.python.org/3/library/stdtypes.html#list" title="builtins.list"><span>word_spans</span></a><span>,</span> <a href="https://pytorch.org/docs/stable/tensors.html#torch.Tensor" title="torch.Tensor"><span>alignment_scores</span></a><span>)</span>
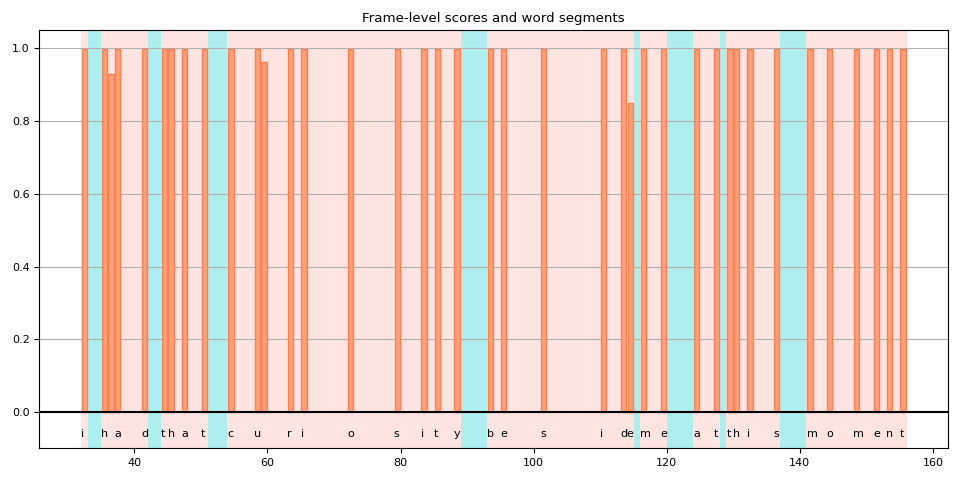
In this plot, the blank tokens are those highlighted area without vertical bar. You can see that there are blank tokens which are interpreted as part of a word (highlighted red), while the others (highlighted blue) are not.
One reason for this is because the model was trained without a label for the word boundary. The blank tokens are treated not just as repeatation but also as silence between words.
But then, a question arises. Should frames immediately after or near the end of a word be silent or repeat?
In the above example, if you go back to the previous plot of spectrogram and word regions, you see that after “y” in “curiosity”, there is still some activities in multiple frequency buckets.
Would it be more accurate if that frame was included in the word?
Unfortunately, CTC does not provide a comprehensive solution to this. Models trained with CTC are known to exhibit “peaky” response, that is, they tend to spike for an aoccurance of a label, but the spike does not last for the duration of the label. (Note: Pre-trained Wav2Vec2 models tend to spike at the beginning of label occurances, but this not always the case.)
[Zeyer et al., 2021] has in-depth alanysis on the peaky behavior of CTC. We encourage those who are interested understanding more to refer to the paper. The following is a quote from the paper, which is the exact issue we are facing here.
Peaky behavior can be problematic in certain cases, e.g. when an application requires to not use the blank label, e.g. to get meaningful time accurate alignments of phonemes to a transcription.
Advanced: Handling transcripts with <star> token
Now let’s look at when the transcript is partially missing, how can we improve alignment quality using the <star> token, which is capable of modeling any token.
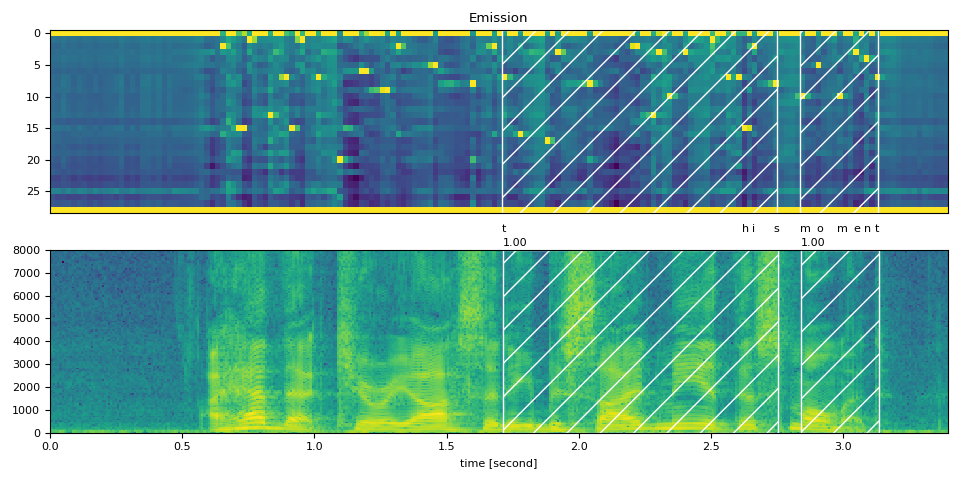
Here we use the same English example as used above. But we remove the beginning text “i had that curiosity beside me at” from the transcript. Aligning audio with such transcript results in wrong alignments of the existing word “this”. However, this issue can be mitigated by using the <star> token to model the missing text.
First, we extend the dictionary to include the <star> token.
Next, we extend the emission tensor with the extra dimension corresponding to the <star> token.
The following function combines all the processes, and compute word segments from emission in one-go.
Full Transcript
Partial Transcript with <star> token
Now we replace the first part of the transcript with the <star> token.
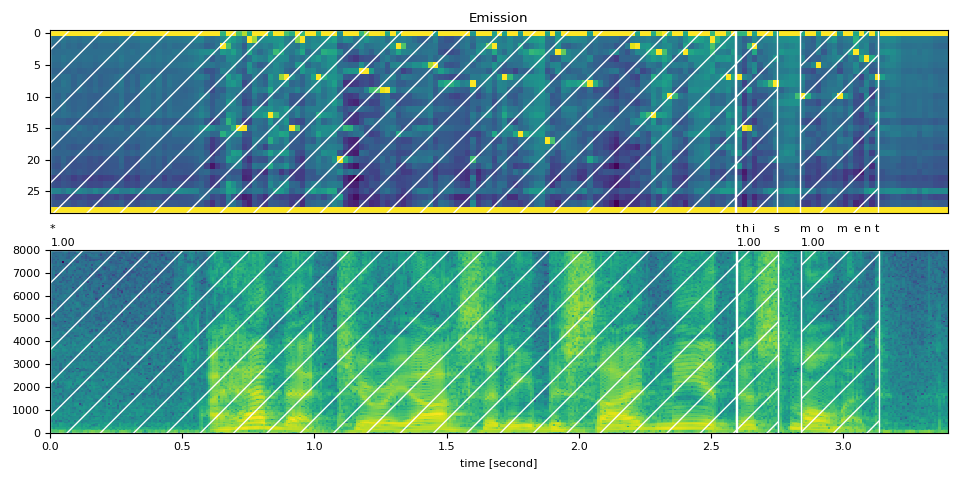
<span></span>* (1.00): 0.000 - 2.595 sec
Your browser does not support the audio element.
<span></span>this (1.00): 2.595 - 2.756 sec
Your browser does not support the audio element.
<span></span>moment (1.00): 2.837 - 3.138 sec
Your browser does not support the audio element.
Partial Transcript without <star> token
As a comparison, the following aligns the partial transcript without using <star> token. It demonstrates the effect of <star> token for dealing with deletion errors.
Conclusion
In this tutorial, we looked at how to use torchaudio’s forced alignment API to align and segment speech files, and demonstrated one advanced usage: How introducing a <star> token could improve alignment accuracy when transcription errors exist.
Acknowledgement
Thanks to Vineel Pratap and Zhaoheng Ni for developing and open-sourcing the forced aligner API.
Total running time of the script: ( 0 minutes 12.079 seconds)