Title: Few-Shot Keyword Spotting in Any Language
Authors: Mark Mazumder, Colby Banbury, Josh Meyer, Pete Warden, Vijay Janapa Reddi
Published: 3rd April 2021 (Saturday) @ 17:27:37
Link: http://arxiv.org/abs/2104.01454v4
Abstract
We introduce a few-shot transfer learning method for keyword spotting in any language. Leveraging open speech corpora in nine languages, we automate the extraction of a large multilingual keyword bank and use it to train an embedding model. With just five training examples, we fine-tune the embedding model for keyword spotting and achieve an average F1 score of 0.75 on keyword classification for 180 new keywords unseen by the embedding model in these nine languages. This embedding model also generalizes to new languages. We achieve an average F1 score of 0.65 on 5-shot models for 260 keywords sampled across 13 new languages unseen by the embedding model. We investigate streaming accuracy for our 5-shot models in two contexts: keyword spotting and keyword search. Across 440 keywords in 22 languages, we achieve an average streaming keyword spotting accuracy of 87.4% with a false acceptance rate of 4.3%, and observe promising initial results on keyword search.
Multilingual Embedding Model (§3.1)
Network architecture is summarized in Figure 1
We repurpose the output of the penultimate layer of a simple keyword classifier as our embedding representation in our few-shot experiments.
- Our classifier uses TensorFlow Lite Micro’s [17] microfrontend spectrogram [18] as 49x40x1 inputs.
- It contains approximately 11 million parameters and consists of a randomly-initialized EfficientNet-B0 implementation from Keras [19], followed by a global average pooling layer, two dense layers of 2048 units with ReLU activations, and a penultimate 1024-unit SELU activation [20] layer, before the classifier’s 761-category softmax output. We chose SELU activations for their self-normalizing properties.
- The classifier is trained on 760 words across nine languages (listed in Table 1); and
- 1.4 million samples in total (Sec. 3.3).
- We select the most common words in each language; and
- filter by character length of 3 or higher to discard brief words and stop words.
- Each extraction is padded with silence to one second in length
- We also include a background noise category in the output
- 10% of all training samples consisting solely of noise sampled from background noise examples in Google’s Speech Commands A Dataset for Limited-Vocabulary Speech Recognition
- Keyword samples are augmented with
- random 100ms timeshifts
- background noise multiplexed at 10% SNR; and
- SpecAugment
Figure 1
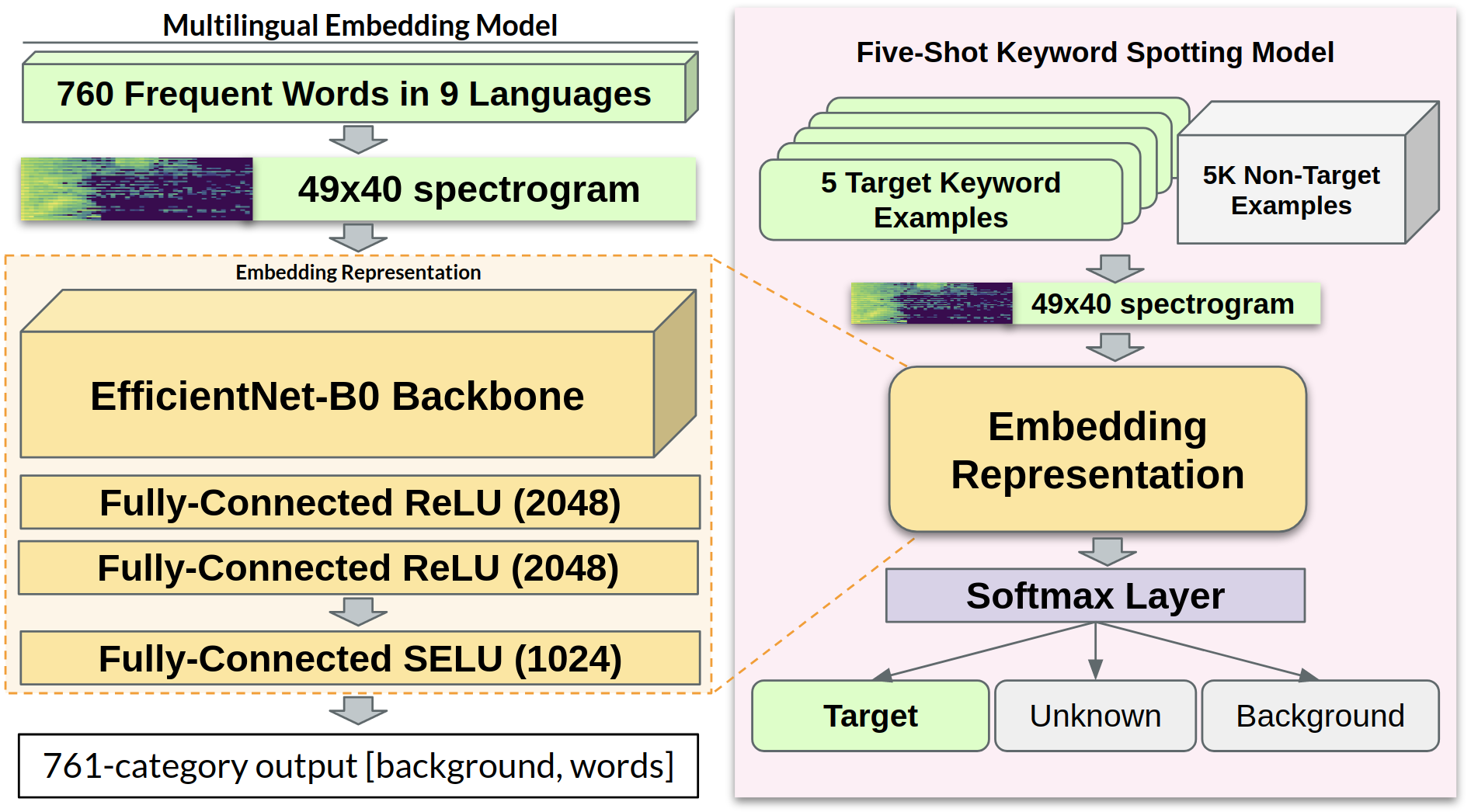
Multilingual Embedding Representation: (a) To learn a multilingual embedding for keyword feature extraction, we train a classifier on 760 keywords totaling 1.4M samples in nine languages, and use the output of the penultimate layer of our classifier as a feature vector for arbitrary keywords in any language. (b) To train a new KWS model, we fine-tune a 3-category classifier using just 5 target examples and 128 non-target samples from a precomputed “unknown” keyword bank.