Optimizing builds with cache management | Docker Docs
Excerpt
Improve your build speed with effective use of the build cache
When you build the same Docker image multiple times, knowing how to optimize the build cache is a great tool for making sure the builds run fast.
How does the build cache work?
Understanding Docker’s build cache helps you write better Dockerfiles that result in faster builds.
The following example shows a small Dockerfile for a program written in C.
# syntax=docker/dockerfile:1
FROM ubuntu:latest
RUN apt-get update && apt-get install -y build-essentials
COPY main.c Makefile /src/
WORKDIR /src/
RUN make build
Each instruction in this Dockerfile translates to a layer in your final image. You can think of image layers as a stack, with each layer adding more content on top of the layers that came before it:

Whenever a layer changes, that layer will need to be re-built. For example, suppose you make a change to your program in the main.c file. After this change, the COPY command will have to run again in order for those changes to appear in the image. In other words, Docker will invalidate the cache for this layer.
If a layer changes, all other layers that come after it are also affected. When the layer with the COPY command gets invalidated, all layers that follow will need to run again, too:
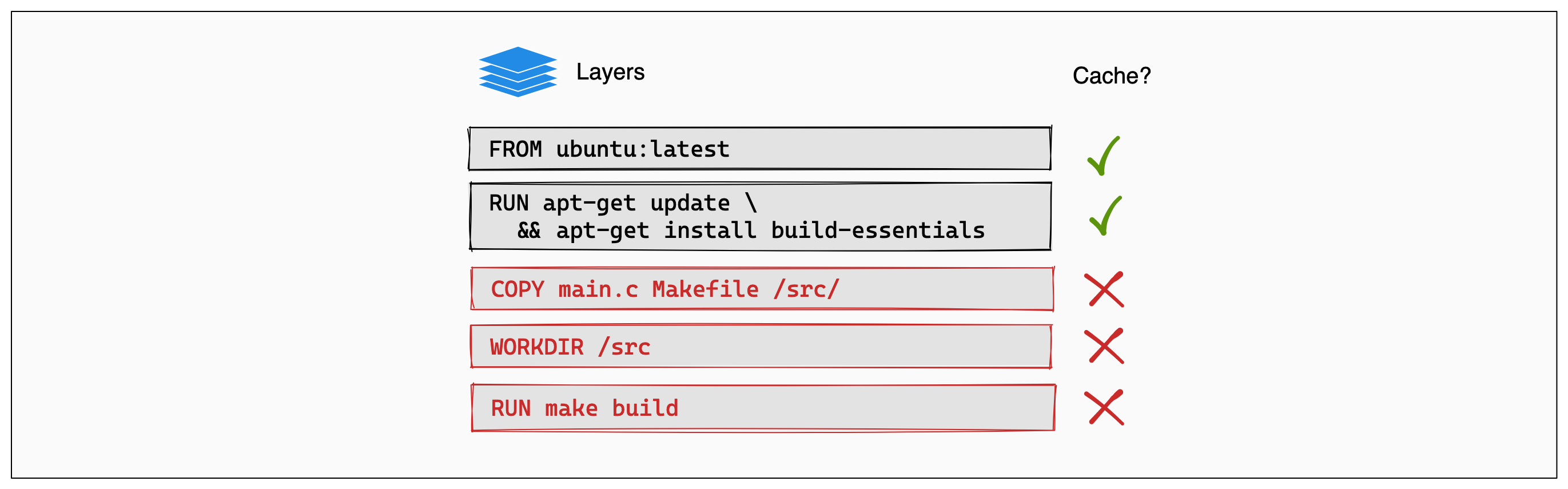
And that’s the Docker build cache in a nutshell. Once a layer changes, then all downstream layers need to be rebuilt as well. Even if they wouldn’t build anything differently, they still need to re-run.
Note
Suppose you have a
RUN apt-get update && apt-get upgrade -ystep in your Dockerfile to upgrade all the software packages in your Debian-based image to the latest version.This doesn’t mean that the images you build are always up to date. Rebuilding the image on the same host one week later will still get you the same packages as before. The only way to force a rebuild is by making sure that a layer before it has changed, or by clearing the build cache using
docker builder prune.
How can I use the cache efficiently?
Now that you understand how the cache works, you can begin to use the cache to your advantage. While the cache will automatically work on any docker build that you run, you can often refactor your Dockerfile to get even better performance. These optimizations can save precious seconds (or even minutes) off of your builds.
Order your layers
Putting the commands in your Dockerfile into a logical order is a great place to start. Because a change causes a rebuild for steps that follow, try to make expensive steps appear near the beginning of the Dockerfile. Steps that change often should appear near the end of the Dockerfile, to avoid triggering rebuilds of layers that haven’t changed.
Consider the following example. A Dockerfile snippet that runs a JavaScript build from the source files in the current directory:
# syntax=docker/dockerfile:1
FROM node
WORKDIR /app
COPY . . # Copy over all files in the current directory
RUN npm install # Install dependencies
RUN npm build # Run build
This Dockerfile is rather inefficient. Updating any file causes a reinstall of all dependencies every time you build the Docker image even if the dependencies didn’t change since last time!
Instead, the COPY command can be split in two. First, copy over the package management files (in this case, package.json and yarn.lock). Then, install the dependencies. Finally, copy over the project source code, which is subject to frequent change.
# syntax=docker/dockerfile:1
FROM node
WORKDIR /app
COPY package.json yarn.lock . # Copy package management files
RUN npm install # Install dependencies
COPY . . # Copy over project files
RUN npm build # Run build
By installing dependencies in earlier layers of the Dockerfile, there is no need to rebuild those layers when a project file has changed.
Keep layers small
One of the best things you can do to speed up image building is to just put less stuff into your build. Fewer parts means the cache stay smaller, but also that there should be fewer things that could be out-of-date and need rebuilding.
To get started, here are a few tips and tricks:
Don’t include unnecessary files
Be considerate of what files you add to the image.
Running a command like COPY . /src will copy your entire build context into the image. If you’ve got logs, package manager artifacts, or even previous build results in your current directory, those will also be copied over. This could make your image larger than it needs to be, especially as those files are usually not useful.
Avoid adding unnecessary files to your builds by explicitly stating the files or directories you intend to copy over. For example, you might only want to add a Makefile and your src directory to the image filesystem. In that case, consider adding this to your Dockerfile:
COPY ./src ./Makefile /src
As opposed to this:
You can also create a .dockerignore file, and use that to specify which files and directories to exclude from the build context.
Use your package manager wisely
Most Docker image builds involve using a package manager to help install software into the image. Debian has apt, Alpine has apk, Python has pip, NodeJS has npm, and so on.
When installing packages, be considerate. Make sure to only install the packages that you need. If you’re not going to use them, don’t install them. Remember that this might be a different list for your local development environment and your production environment. You can use multi-stage builds to split these up efficiently.
Use the dedicated RUN cache
The RUN command supports a specialized cache, which you can use when you need a more fine-grained cache between runs. For example, when installing packages, you don’t always need to fetch all of your packages from the internet each time. You only need the ones that have changed.
To solve this problem, you can use RUN --mount type=cache. For example, for your Debian-based image you might use the following:
RUN \
--mount=type=cache,target=/var/cache/apt \
apt-get update && apt-get install -y git
Using the explicit cache with the --mount flag keeps the contents of the target directory preserved between builds. When this layer needs to be rebuilt, then it’ll use the apt cache in /var/cache/apt.
Minimize the number of layers
Keeping your layers small is a good first step, and the logical next step is to reduce the number of layers that you have. Fewer layers mean that you have less to rebuild, when something in your Dockerfile changes, so your build will complete faster.
The following sections outline some tips you can use to keep the number of layers to a minimum.
Use an appropriate base image
Docker provides over 170 pre-built official imagesopen_in_new for almost every common development scenario. For example, if you’re building a Java web server, use a dedicated image such as eclipse-temurinopen_in_new. Even when there’s not an official image for what you might want, Docker provides images from verified publishersopen_in_new and open source partnersopen_in_new that can help you on your way. The Docker community often produces third-party images to use as well.
Using official images saves you time and ensures you stay up to date and secure by default.
Use multi-stage builds
Multi-stage builds let you split up your Dockerfile into multiple distinct stages. Each stage completes a step in the build process, and you can bridge the different stages to create your final image at the end. The Docker builder will work out dependencies between the stages and run them using the most efficient strategy. This even allows you to run multiple builds concurrently.
Multi-stage builds use two or more FROM commands. The following example illustrates building a simple web server that serves HTML from your docs directory in Git:
# syntax=docker/dockerfile:1
# stage 1
FROM alpine as git
RUN apk add git
# stage 2
FROM git as fetch
WORKDIR /repo
RUN git clone https://github.com/your/repository.git .
# stage 3
FROM nginx as site
COPY --from=fetch /repo/docs/ /usr/share/nginx/html
This build has 3 stages: git, fetch and site. In this example, git is the base for the fetch stage. It uses the COPY --from flag to copy the data from the docs/ directory into the Nginx server directory.
Each stage has only a few instructions, and when possible, Docker will run these stages in parallel. Only the instructions in the site stage will end up as layers in the final image. The entire git history doesn’t get embedded into the final result, which helps keep the image small and secure.
Combine commands together wherever possible.
Most Dockerfile commands, and RUN commands in particular, can often be joined together. For example, instead of using RUN like this:
RUN echo "the first command"
RUN echo "the second command"
It’s possible to run both of these commands inside a single RUN, which means that they will share the same cache! This is achievable using the && shell operator to run one command after another:
RUN echo "the first command" && echo "the second command"
# or to split to multiple lines
RUN echo "the first command" && \
echo "the second command"
Another shell feature that allows you to simplify and concatenate commands in a neat way are heredocsopen_in_new. It enables you to create multi-line scripts with good readability:
RUN <<EOF
set -e
echo "the first command"
echo "the second command"
EOF
(Note the set -e command to exit immediately after any command fails, instead of continuing.)
Other resources
For more information on using cache to do efficient builds, see: