Title: Interpretable Convolutional Filters with SincNet
Authors: Mirco Ravanelli, Yoshua Bengio
Published: 23rd November 2018 (Friday) @ 23:13:09
Link: http://arxiv.org/abs/1811.09725v2
Abstract
Deep learning is currently playing a crucial role toward higher levels of artificial intelligence. This paradigm allows neural networks to learn complex and abstract representations, that are progressively obtained by combining simpler ones. Nevertheless, the internal “black-box” representations automatically discovered by current neural architectures often suffer from a lack of interpretability, making of primary interest the study of explainable machine learning techniques. This paper summarizes our recent efforts to develop a more interpretable neural model for directly processing speech from the raw waveform. In particular, we propose SincNet, a novel Convolutional Neural Network (CNN) that encourages the first layer to discover more meaningful filters by exploiting parametrized sinc functions. In contrast to standard CNNs, which learn all the elements of each filter, only low and high cutoff frequencies of band-pass filters are directly learned from data. This inductive bias offers a very compact way to derive a customized filter-bank front-end, that only depends on some parameters with a clear physical meaning. Our experiments, conducted on both speaker and speech recognition, show that the proposed architecture converges faster, performs better, and is more interpretable than standard CNNs.
My summary
Background: We’re using convolutional initial layers in architectures for speech processing. We’re going to use a battery of conv layers (extract and aggregate local features) and then pass this to an LSTM as the higher-level layer with the goal of doing ASR and speaker recognition.
Mirco Ravanelli and Yoshua Bengio observe that convolutional filters don’t learn filters that are meaningful to humans - even if they’re meaningful to the network. They contend the first convolutional layer is the most important since it directly marshals the data from the waveform input, producing the meaningful output for the subsequent, “higher” layers.
The downside of raw speech processing lies in the possible lack of interpretability of the filter bank learned in the first convolutional layer. According to us, the latter layer is arguably the most critical part of current waveform-based CNNs. This layer deals with high-dimensional inputs and is also more affected by vanishing gradient problems, especially when employing very deep architectures.
They propose learning band-pass filters for these first-convolutional-layer kernels. This definitely seems like an intuitive choice, for example if you consider the argument that many models like Whisper are trained on (mel-)spectrograms, which are engineered frequency band features. Remember:
where and are low and high cutoff frequencies, and rect is the magnitude frequency-domain rectangular function.
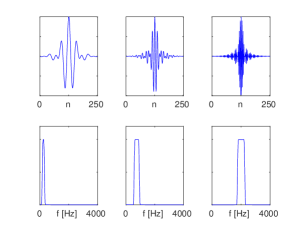
Figure 2: Examples of filters learned by a standard CNN and by the proposed SincNet (using the Librispeech corpus on a speaker-id task). The first row reports the filters in the time domain, while the second one shows their magnitude frequency response.
The magnitude of a band-pass filter in the frequency domain is also expressed as the difference between two rectangular functions that represent low-pass filters. They propose replacing the kernel in the convolution with another function, , which will effectively act as a band-pass filter. But remember they have to do this in the time domain because they are working with direct waveform input.
So they give the standard equation formulating what a CNN does, namely convolving an input waveform with kernels in the time domain:
- is a chunk of the speech signal
- is the filter of length
- is the filtered output
Most deep learning toolkits actually compute correlation rather than convolution. The obtained flipped (mirrored) filters do not affect the results.
While standard CNNs learn the kernel elements (which apparently I learnt thanks to Mirco and Yoshua are called taps) from data, their proposed SincNet uses the predefined function for the convolution and depends on exactly 2 learnable parameters per function: the low and high cutoff frequency equivalents in the time domain (represented by a ).
So the convolution now looks like this:
Then, after returning to the time domain via the inverse Fourier transform, the reference function becomes:
where the eponymous function is defined as .
The cut-off frequencies can be initialized randomly in the range , where represents the sampling frequency of the input signal. As an alternative, filters can be initialized with the cutoff frequencies of the mel-scale filter-bank, which has the advantage of directly allocating more filters in the lower part of the spectrum, where crucial speech information is located. To ensure and , the previous equation is actually fed by the following parameters:
Some interesting notes from them:
- Note that no bounds have been imposed to force to be smaller than the Nyquist frequency, since we observed that this constraint is naturally fulfilled during training.
- Moreover, the gain of each filter is not learned at this level. This parameter is managed by the subsequent layers, which can easily attribute more or less importance to each filter output.
- An ideal bandpass filter (i.e., a filter where the passband is perfectly flat and the attenuation in the stopband is infinite) requires an infinite number of elements . Any truncation of thus inevitably leads to an approximation of the ideal filter, characterized by ripples in the passband and limited attenuation in the stopband.
- They adopt the Hamming window to address this issue but find that others like the Hann, Blackman, and Kaiser windows also work with SincNet
Model Properties, or Advantages of SincNet
All of this - SincNet - brings three clear advantages.
Faster convergence
The proposed approach actually implements a natural inductive bias, utilizing knowledge about the filter shape (similar to feature extraction methods generally deployed on this task) while retaining flexibility to adapt to data. This prior knowledge makes learning the filter characteristics much easier, helping SincNet to converge significantly faster to a better solution.
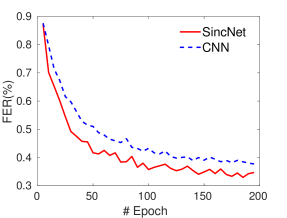
Figure 3: Frame Error Rate (%) obtained on speaker-id with the TIMIT corpus (using heldout data).
Fewer Parameters
SincNet drastically reduces the number of parameters in the first convolutional layer. For instance, if we consider a layer composed of F filters of length L, a standard CNN employs F · L parameters, against the 2F considered by SincNet. If F = 80 and L = 100, we employ 8k parameters for the CNN and only 160 for SincNet. Moreover, if we double the filter length L, a standard CNN doubles its parameter count (e.g., we go from 8k to 16k), while SincNet has an unchanged parameter count (only two parameters are employed for each filter, regardless its length L). This offers the possibility to derive very selective filters with many taps, without actually adding parameters to the optimization problem. Moreover, the compactness of the SincNet architecture makes it suitable in the few sample regime.
Interpretability
The filter bank, in fact, only depends on parameters with a clear physical meaning.
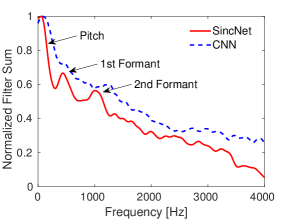
Figure 4: Cumulative frequency response of SincNet and CNN filters on speaker-id.
The cumulative frequency response is obtained by summing up all the discovered filters and is useful to highlight which frequency bands are covered by the learned filters.
Three main peaks stand out from the SincNet plot (red line in Figure 4).
- First peak: Pitch region. The average pitch is 133 Hz for a male and 234 for a female
- Second Peak (approximately located at 500 Hz): Mainly captures first formants, whose average value over the various English vowels is indeed 500 Hz
- Third peak (ranging from 900 to 1400 Hz) captures some important second formants, such as the second formant of the vowel /a/, which is located on average at 1100 Hz
This filter-bank configuration indicates that SincNet has successfully adapted its characteristics to address speaker identification. Conversely, the standard CNN does not exhibit such a meaningful pattern: the CNN filters tend to correctly focus on the lower part of the spectrum, but peaks tuned on first and second formants do not clearly appear.
As one can observe from Fig. 4, the CNN curve stands above the SincNet one. SincNet, in fact, learns filters that are, on average, more selective than CNN ones, possibly better capturing narrow-band speaker clues.

Figure 5 shows the cumulative frequency response of a CNN and SincNet obtained on a noisy speech recognition task. In this experiment, we have artificially corrupted TIMIT with a significant quantity of noise in the band between 2.0 and 2.5 kHz (see the spectrogram) and we have analyzed how fast the two architectures learn to avoid such a useless band…SincNet shows a visible valley in the cumulative spectrum even after processing only one hour of speech, while CNN has only learned to give more importance to the lower part of the spectrum.
Figure 5. Cumulative frequency responses obtained on a speech recognition task trained with a noisy version of TIMIT. As shown in the spectrogram, noise has been artificially added into the band 2.0-2.5 kHz. Both the CNN and SincNet learn to avoid the noisy band, but SincNet learns it much faster, after processing only one hour of speech.
Results
Speaker Recognition
Table 1 reports the Classification Error Rates (CER%) achieved on a speaker-id task. The table shows that SincNet outperforms other systems on both TIMIT (462 speakers) and Librispeech (2484 speakers) datasets.
The gap with a standard CNN fed by raw waveform is larger on TIMIT, confirming the effectiveness of SincNet when few training data are available. Although this gap is reduced when LibriSpeech is used, we still observe a 4% relative improvement that is also obtained with faster convergence (1200 vs 1800 epochs).
Standard FBANKs provide results comparable to SincNet only on TIMIT, but are significantly worse than our architecture when using Librispech. With few training data, the network cannot discover filters that are much better than that of FBANKs, but with more data a customized filter-bank is learned and exploited to improve the performance.
| TIMIT | LibriSpeech | |
|---|---|---|
| DNN-MFCC | 0.99 | 2.02 |
| CNN-FBANK | 0.86 | 1.55 |
| CNN-Raw | 1.65 | 1.00 |
| SincNet | 0.85 | 0.96 |
Speech Recognition
To ensure a more accurate comparison between the architectures, five experiments varying the initialization seeds were conducted for each model and corpus. Table 3 thus reports the average speech recognition performance. Standard deviations, not reported here, range between 0.15 and 0.2 for all the experiments.
| Method | TIMIT | DIRHA |
|---|---|---|
| CNN-FBANK | 18.3 | 40.1 |
| CNN-Raw waveform | 18.1 | 40.0 |
| SincNet-Raw waveform | 17.2 | 37.2 |
For all the datasets, SincNet outperforms CNNs trained on both standard FBANK and raw waveforms. The latter result confirms the effectiveness of SincNet not only in close-talking scenarios but also in challenging noisy conditions characterized by the presence of both noise and reverberation.
Questionsquestion
- What happened to the learnings from this paper? I would assume that constraining your convolutions to be band-pass filters is too strong and this reduction in model flexibility diminishes performance.
- This constraint isn’t relevant to Whisper since its trained on mel-spectrograms.
- You’re learning 2 parameters per filter instead of the kernel size parameters
- But has anyone recently tried sota ASR models with this constraint?
- Added to Questions: What is the significance of Finite Impulse Response (FIR) filters? Why is it important that they are finite response and what would happen if they were Infinite Response?