The Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
I discussed the Swin Transformer: Hierarchical Vision Transformer using Shifted Windows by Ze Liu and colleagues published at ICCV ‘21 at the PINLab Reading Group on the 3d November 2021.
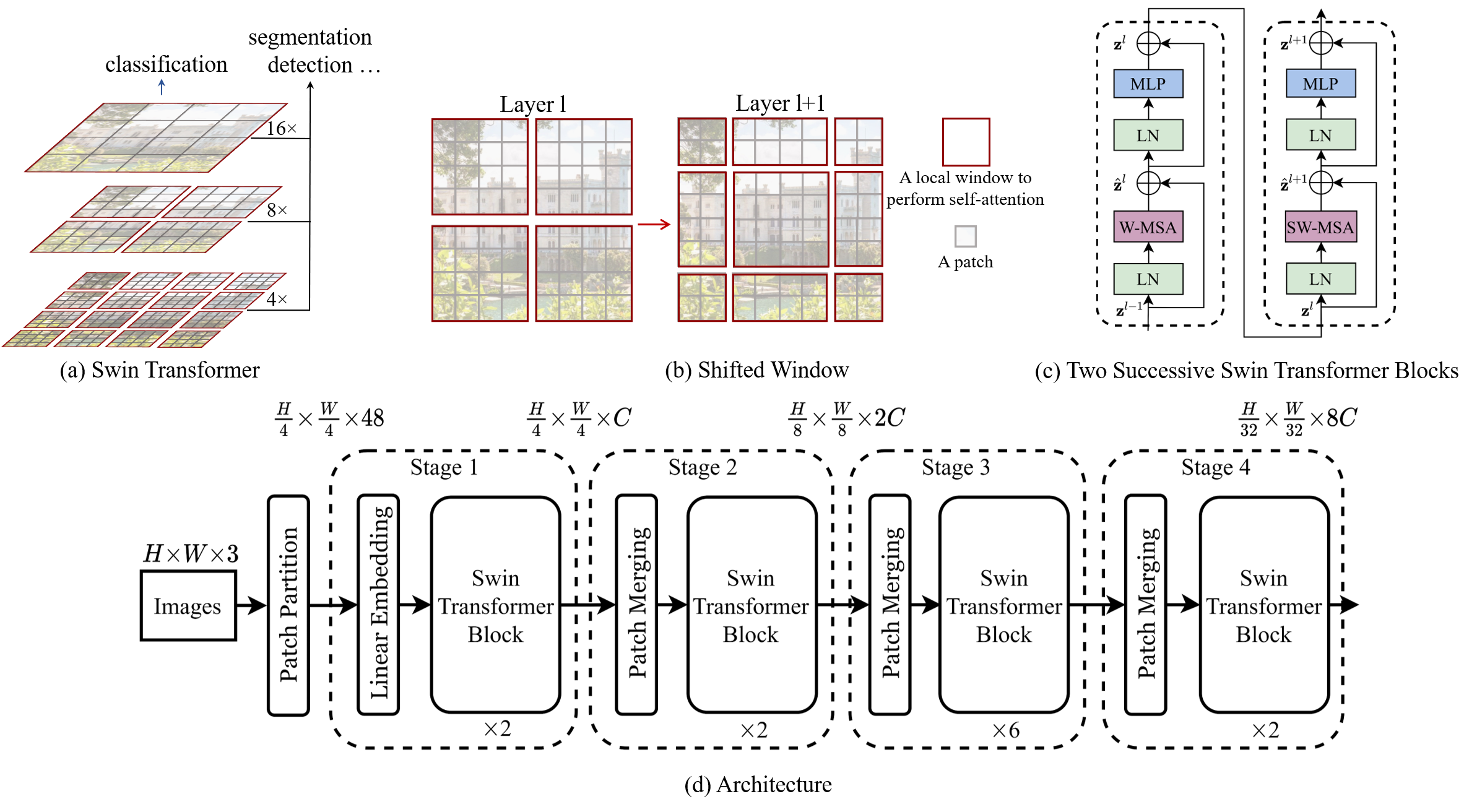
The Swin Transformer modifies the base Transformer to enforce a form of local attention, rendering the computational complexity linear in the image size, and combines this with a hierarchical architecture that introduces inductive biases similar to those of CNNs for general computer vision backbones. Within blocks of the architecture, it uses “shifted windows”, i.e. windows partitionings that vary in alternating Transformer Blocks implementing self-attention to enable information flow between windows, to (further) overcome the lack of global self-attention. Significantly, it surpasses state-of-the-art results in dense prediction tasks, i.e. those that operate at the pixel level like Semantic Segmentation and Object Detection.
My slides are available for download here
Resources
Swin Transformer
Datasets
- COCO Detection Evaluation (including Metrics): https://cocodataset.org/#detection-eval
- ADE20K Dataset: https://groups.csail.mit.edu/vision/datasets/ADE20K/
Baselines
- Data-efficient Image Transformer: https://paperswithcode.com/method/deit
- Vision Transformer: https://paperswithcode.com/method/vision-transformer
State of the Art
- ImageNet Classification SotA on Papers with Code: https://paperswithcode.com/sota/image-classification-on-imagenet
- ADE20K val Semantic Segmentation SotA on Papers with Code: https://paperswithcode.com/sota/semantic-segmentation-on-ade20k-val
- Object Detection on COCO test-dev SotA on Papers with Code: https://paperswithcode.com/sota/object-detection-on-coco